Quantifying Known and Unknown Metrics in ADAS and AV Development
With large volumes of data generated in AV development from drives and simulations, making effective use of data can be challenging. The Applied Inuition team discusses how to effectively use data to track progress on known requirements and uncover gaps in coverage.
November 4, 2020 • 7 min read
Developing autonomous vehicles (AVs) that guarantee safety and gain the trust of consumers requires training, validating, and testing algorithms with an enormous volume of data. Throughout the industry, no consensus exists on exactly how much data is enough to train a system to navigate all the high-risk, long-tail events. Both drives and simulations produce massive amounts of data and the analysis of such data is complex due to its non-binary nature and the complexity of debugging self-driving cars.
Several companies are attempting to address the challenge of managing large volumes of AV data by bringing more efficiency to data warehousing and infrastructure (e.g., BMW’s High Performance D3 platform). In this blog, the Applied Inuition team instead focuses on the best practices seen for using drive and simulation data to identify and track requirements and fill data gaps.
Measuring Progress: What Is Most Important?
The most important thing to uncover from drive and simulation data analysis is if progress is being made for the AV program consistently or week-over-week. To understand this, it is helpful to think about two questions: 1) How well does the AV system perform against known requirements? 2) What are the unknown scenarios that should be solved next?
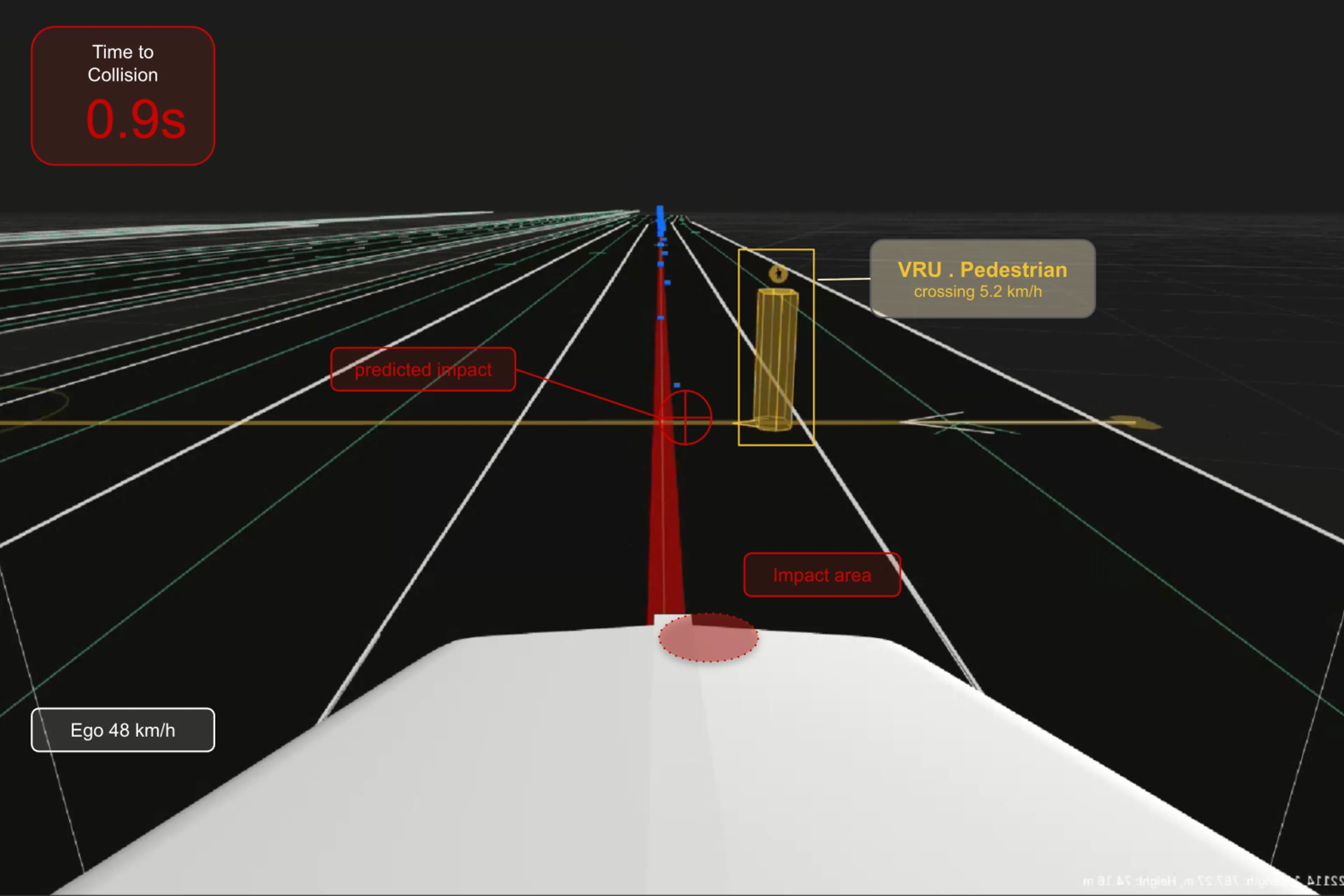
Measuring what is known: tracking KPIs for autonomy
Organizations should track a set of development key performance indicators (KPIs) across dimensions such as comfort (e.g. max jerk), time to collision, and required safety buffers in specific scenarios. These KPIs are designed to measure the safety and desired comfort of autonomous driving systems. To measure performance against KPIs, development teams should map drive data and simulation test results to known requirements and evaluate if the system meets the desired thresholds.
For example, in the case of a highway lane-keep ODD, an organization may track the autonomous vehicle stack’s lateral control errors and how road curvature affects these errors. The organization should aggregate all of its data by road curvature and pull out data in which errors don’t pass the organization’s thresholds. To track KPIs, it is advisable to measure them week-over-week using the same scenarios or re-calculate KPIs over old drives (instead of comparing them to new drives) in order to minimize the impact of variance from external factors such as changes in foliage or road conditions.
Figure 1: Observer failures in a tiled view
In addition to custom KPIs, there are safety models that are widely adopted in the AV industry. For example, Mobileye’s open-source Responsibility Sensitive Safety (RSS) is a mathematical model to evaluate whether autonomous vehicles behave safely with respect to human intuition. Using this mathematical model, it is possible to evaluate the ego’s ability to follow abstract safety concepts such as ‘maintain safe distance with a car in front of you.’ Scores for these KPIs may be calculated across all data and in specific scenarios.
While most AV development programs may not be ready to answer “is this stack safe?,” it is still important to quantify if the stack is safer this week than last. Tracking KPIs allows the quantification of the progress being made in an AV development program.
Finding what is not known: coverage gaps
In AV development, there will still be blind spots since many scenarios are not known ahead of time. We have described SOTIF and corresponding coverage approaches in the previous post about domain coverage.
There are a few approaches to identifying gaps in the drive data. The most obvious approach is creating reports that visualize details such as with what types of actors the system has (or has not) interacted and over which areas of the map the system has (or has not) driven. In addition to geographic map coverage, one could also compare available data to specific map features, such as intersection type, road size, and exit ramps. This type of analysis should highlight where common issues occur and clarify where there is a gap in available data.
A less obvious approach is using the perception stack’s outputs to find where the system is ‘confused’. This approach could be useful when objects are categorized and labeled with high degrees of uncertainty.
Interventions and disengagements are other signals for coverage gaps. Since errors may be propagating from any combination of modules in the AV stack, it may be complex to pinpoint what is causing the overall AV system to fail. Root causing failures would require visualizing sensor data alongside post-sensor fusion bounding boxes and underlying generated metrics and logs of relevant stack modules. Resimulation with different stack versions could also be useful for debugging failures in the real world. A new requirement should be created from the event and added to the organization’s requirements.
Filling the Data Gaps
Identifying these gaps is critical to prioritizing the development team’s focus across feature development, data collection, synthetic data generation and data annotation. One could always drive more in the real world to collect data needed to fill the known gaps, but this approach is not scalable. Depending on the types of missing data, it may be up to luck to encounter edge case scenarios.
A more scalable approach is creating synthetic scenarios. As discussed in the previous post about sensor simulation, procedural generation enables the creation of photorealistic environments quickly and inexpensively using various inputs. It is particularly helpful if the missing data is difficult to come by in the real world or it is necessary to test the ego under multiple variations of the same scenario. Gaps in perception training data may be filled with annotated synthetic data—the Applied Inuition team has previously discussed requirements for synthetic data to be useful for perception system development.
Similarly, when it comes to data annotation, teams would quickly find it infeasible to annotate all collected data.
A common approach to reduce training dataset size is active learning, in which an algorithm is able to interactively query drive data to obtain interesting or uncommon events that are causing confusion in the perception system. Curated snippets could also be obtained by querying data samples similar to the known detection of interest using model embedding comparison. The curated snippets may then be manually labeled and added to the training dataset. With this approach, the proportion of ‘confusing’ data in the training set may be increased while limiting expensive labeling to the highest impact snippets.
Once gaps are identified, the development team should build features to fill these gaps and ensure there are no regressions in the future. This may be achieved with a focused feature sprint that starts with tracking KPIs alongside target requirements and their associated functional scenarios in a custom dashboard. The dashboard may also be used as part of regression analysis following the sprint.
Once the largest gaps in the current stack’s performance are known, those should drive most of the data collection and feature development efforts. This process of identifying gaps to drive development efforts can be repeated cyclically, with continuous analysis of where remaining work can best be applied to improve performance of the system.
Applied Intuition’s Approach
While the best approaches may differ from situation to situation and from team to team, Applied Inuition’s tools help developers measure progress towards development goals by identifying gaps to scenario requirements and detecting anomalies in thousands of hours of drive logs. The analytics and visualization tools enable instant regression and root-cause analyses, facilitate communication across the organization from the engineering team to the executives, and provide automatic insights from large-scale drive logs. If you’re interested in discussing specific approaches to measuring knowns and unknowns, connect with Applied Inuition’s engineers!