Applied Intuition’s Log Management Handbook: Drive Data Exploration (Part 2)
Part 2 of our log management handbook series introduces readers to drive data exploration with a particular emphasis on surfacing interesting events for review.

This blog post is the second in a three-part series highlighting different topics from Applied Intuition’s log data management handbook for autonomous systems development. Read part 1 for an introduction to the log management life cycle and the different workflows powered by drive data. This second part lays out drive data exploration best practices with a particular emphasis on surfacing interesting events. Keep reading to learn more about this topic, or access our full handbook below.
Drive data exploration is an important part of the log management life cycle. After an autonomy program collects drive data files, data processing pipelines convert these files into usable formats, and different teams explore them according to their specific use cases.
In order to extract value from drive data, programs need to process large amounts of the collected data (Figure 1) and build indices to enable faster data retrieval. They can then enrich data with offline algorithms, surface interesting events, visualize data, and analyze system performance and operational design domain (ODD) coverage. While our log management handbook discusses each of these steps in detail, this blog post focuses on surfacing interesting events.
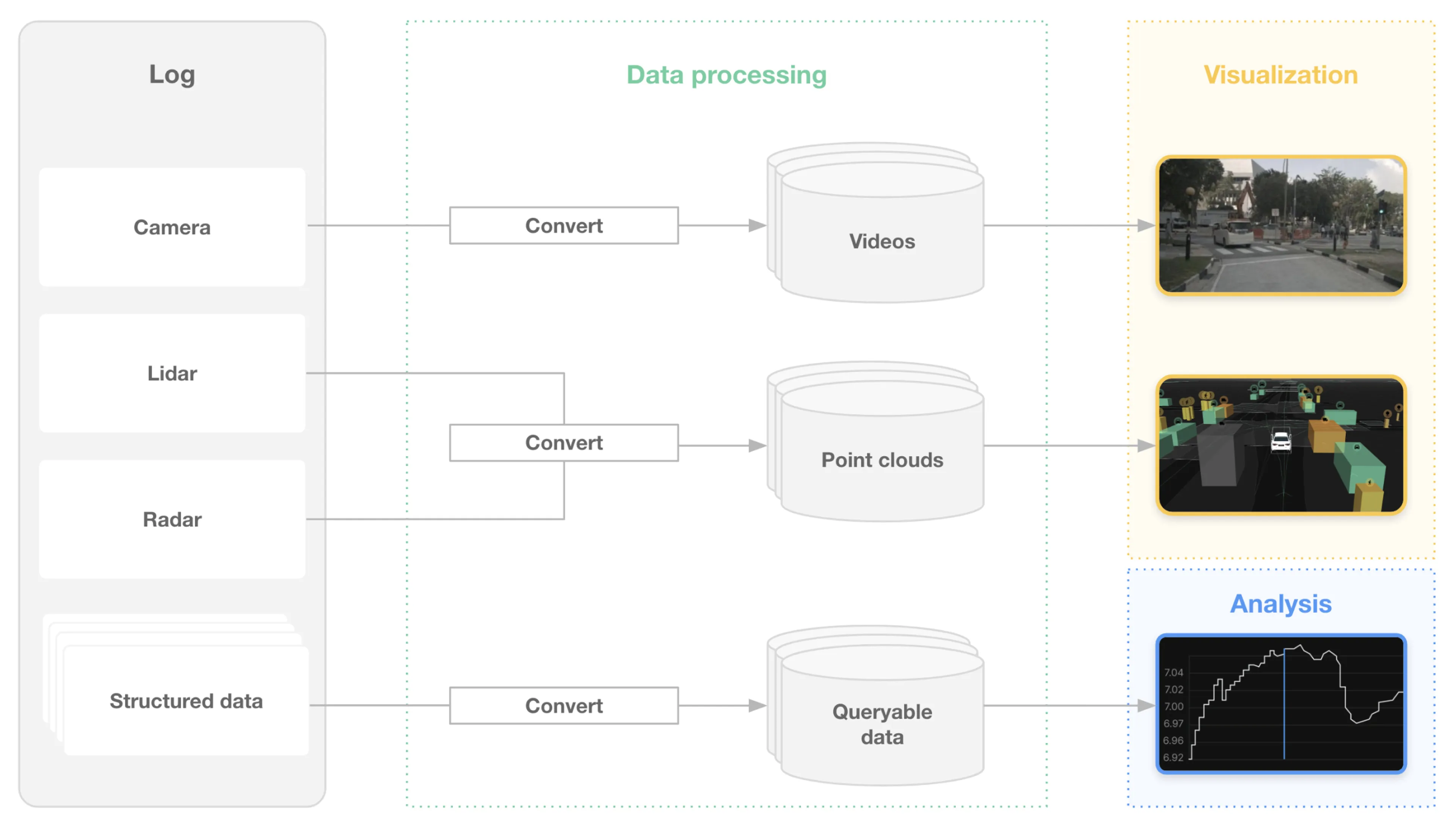
Figure 1: Data processing pipelines operate on drive data to convert it into formats usable for exploration.
The work of triage operations teams, algorithm engineers, and other users of drive data involves identifying relevant events in the drive data and reviewing those events to evaluate the autonomous system’s performance. Today’s SAE Level 2 (L2) and L3 autonomous systems already record events such as hard braking, acceleration, and jerk. The following sections outline which other types of events autonomy programs should surface and how validation, motion planning, and perception teams can best surface these events.
All interventions that occur while an autonomous system is engaged should be surfaced for review. Interventions include operator disengagements (i.e., situations where the safety operator intervenes to disengage autonomous mode in L4 autonomous systems) and system escalations (i.e., situations where the safety operator or the vehicle owner intervenes to take control of an L2 or L3 autonomous system). If available, the surfaced events should include relevant safety operator comments. Safety operator comments can help teams quickly review and root cause events that may have been caused by a system failure. Surfaced events might also contain the autonomous system’s intended maneuver, the behavior of nearby actors, and information such as map information that helps teams classify an event as occurring inside or outside of the autonomous system’s ODD.
Scenario tags assist validation and motion planning teams in evaluating their autonomous system’s performance. Validation teams can use scenario tags to find scenarios that match a specific situation. Scenario tags often combine behavior annotation, map or geographic information, and ODD data. For example, scenario tags help surface scenarios such as “lane change on highway” and “actor cut-in during rain.” Validation teams can then perform aggregate analysis on scenarios with the same tags to understand how the autonomous system tends to perform in specific situations.
Motion planning teams can combine scenario tags to create human descriptions of especially difficult situations. For example, filtering by “vehicle pulling out of parking spot” and “bicyclist adjacent” will surface edge cases that are relevant to every motion planning team.
Autonomous systems development involves abundant unlabeled raw data. Unfortunately, high-quality labels are often expensive to obtain, and labeling common scenarios such as standard highway driving has diminishing returns on perception model performance. A perception model should thus be trained on data that was incorrectly classified by previous versions of the model (Figure 2). Perception teams can implement a process to identify these cases in logged data automatically.
To surface potential errors automatically, perception teams can compare the output of the on-vehicle model to the output of a more powerful offline perception model and find cases where the two models disagree. These discrepancies likely indicate errors in the on-vehicle perception stack and should be sent to a team member for manual review and labeling.
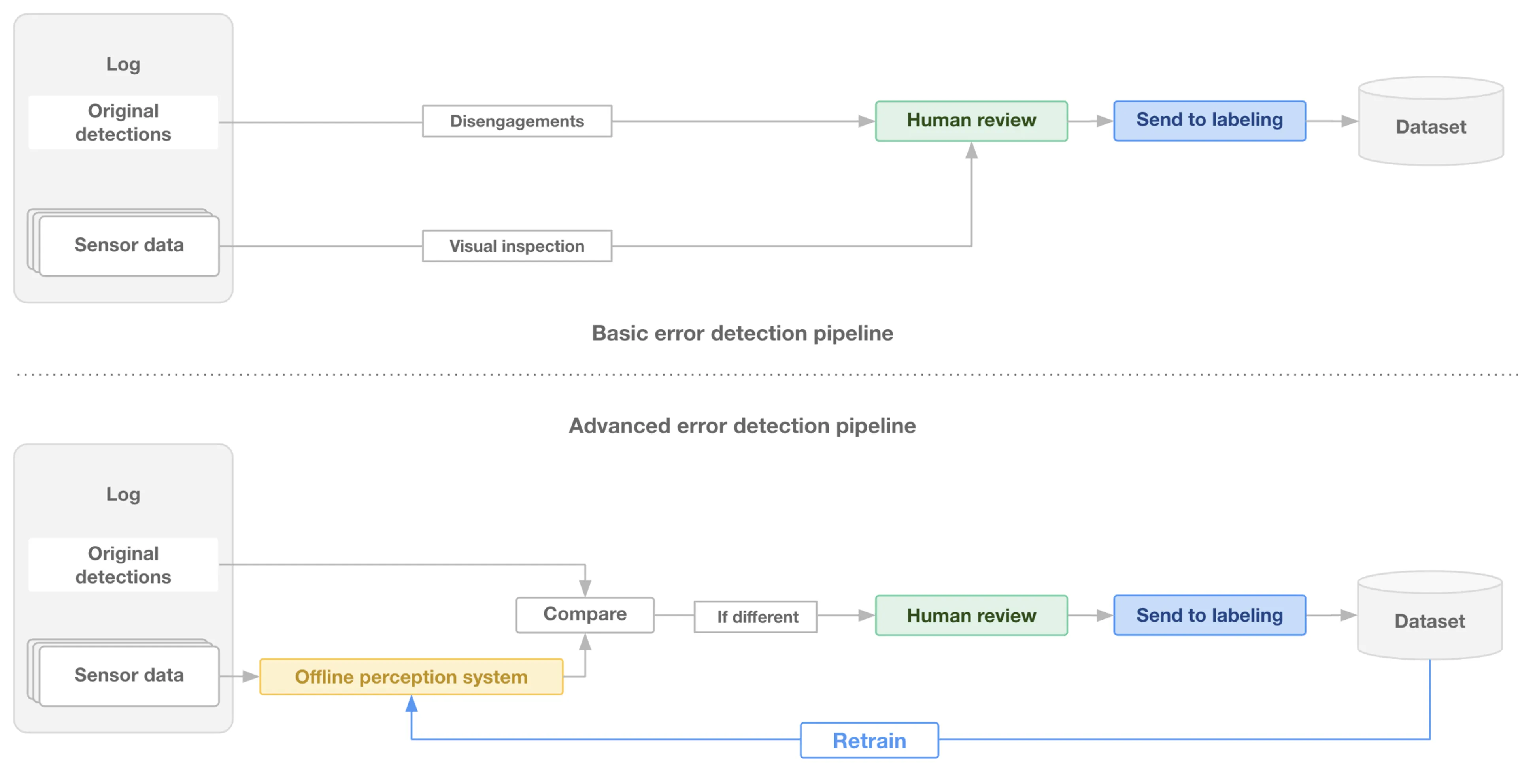
Figure 2: An offline perception system can highlight failures in the on-vehicle perception system. A human review of the disagreements provides final arbitration over which perception system is correct.
Beyond finding specific predefined events, autonomy programs typically find it useful to surface unpredicted anomalies in their drive data for manual review. Anomalies can include known scenarios with unexpected metrics for pre-chosen dimensions (e.g., the most aggressive cut-ins) and unseen edge cases surfaced through machine learning (ML). A common ML-based anomaly detection technique leverages unsupervised learning to detect unexpected data. Teams train an ML model on a subset of the most relevant channels in their drive data to predict the next timestamp based on a window of historical data. This model then runs on a drive data file and surfaces events for which it has the largest prediction gap. These are the cases where the autonomous system behaved in the most unexpected way according to existing data, or a sub-system behaved unpredictably. Automated anomaly detection is an ongoing area of research. However, it is increasingly popular among autonomy programs that face the limits of automation when combing through petabytes of drive data.
Surfacing and reviewing interesting events is an essential step in every autonomy program’s drive data exploration process. Teams can leverage different techniques to surface operator disengagements, system escalations, anomalies, and other events that help validation, perception, and motion planning teams evaluate their autonomous system. To learn about other steps in the drive data exploration process, such as data processing, enrichment, visualization, and analysis, download our full handbook below, and stay tuned for the third and last part of our blog post series.
Contact the Applied Intuition team with your questions about this handbook and learn more about Applied Intuition’s log management solutions on our website.

