From Procedural Generation to Determinism: Approaches to Simulating Synthetic Perception Data for Autonomous Driving
Sensor simulation for autonomous driving systems is an exceedingly difficult task, requiring high-fidelity simulations that could be processed in real-time. There are techniques that could be used to accurately test your perception system.
July 6, 2020 • 8 min read
Simulation is a vital tool for accelerating engineering development across many industries. For autonomous vehicle systems, simulation has traditionally been used for testing motion planning and control algorithms. Re-simulations have been used for perception system development where on-road sensor data is recorded and replayed against different versions of software stacks to test performance. But, these simulations have been predominantly limited to scenarios encountered on real drives.
Another type of simulation that is gaining importance is generating high-quality synthetic sensor data that closely represents real on-road data. The problem with using only on-road data is that enormous amounts of data must be gathered and labeled in order to reach the edges of a perception module's capabilities across Operational Design Domains (ODDs). Further, perception algorithms are overfit to the data that is available and fail outside of the recorded environment and conditions. In contrast, synthetic data could be generated quickly and cheaply, and annotations are automatically created using the underlying knowledge of the simulation environment.
Challenges with Creating Synthetic Perception Data
While synthetic sensor simulation seems obvious at first, it is an exceedingly difficult task. In addition to creating realistic synthetic environments across the world (e.g., San Francisco or Tokyo), simulating each sensor type requires detailed knowledge of the underlying physics and the specifics of different sensors used by the industry. While simulations may sometimes run at orders of magnitude slower than real-time for other applications, autonomous vehicle algorithms require close to real-time performance. This leads to a requirement of multi-fidelity simulations to support different use cases.
Despite the best efforts to model each sensor, there is expected to be a domain gap between the real and synthetic data in the near term. Perception algorithms that are trained on real sensor data and tested on synthetic sensor data (real-to-synthetic) or vice versa (synthetic-to-real) perform differently than real-to-real or synthetic-to-synthetic training and testing. This domain gap is not specific to simulated data; perception algorithms trained using one sensor set on California roads would typically perform poorly on the same roads with a different sensor set. An algorithm trained using the same sensor set on California roads could also perform poorly when tested on roads in another part of the world.
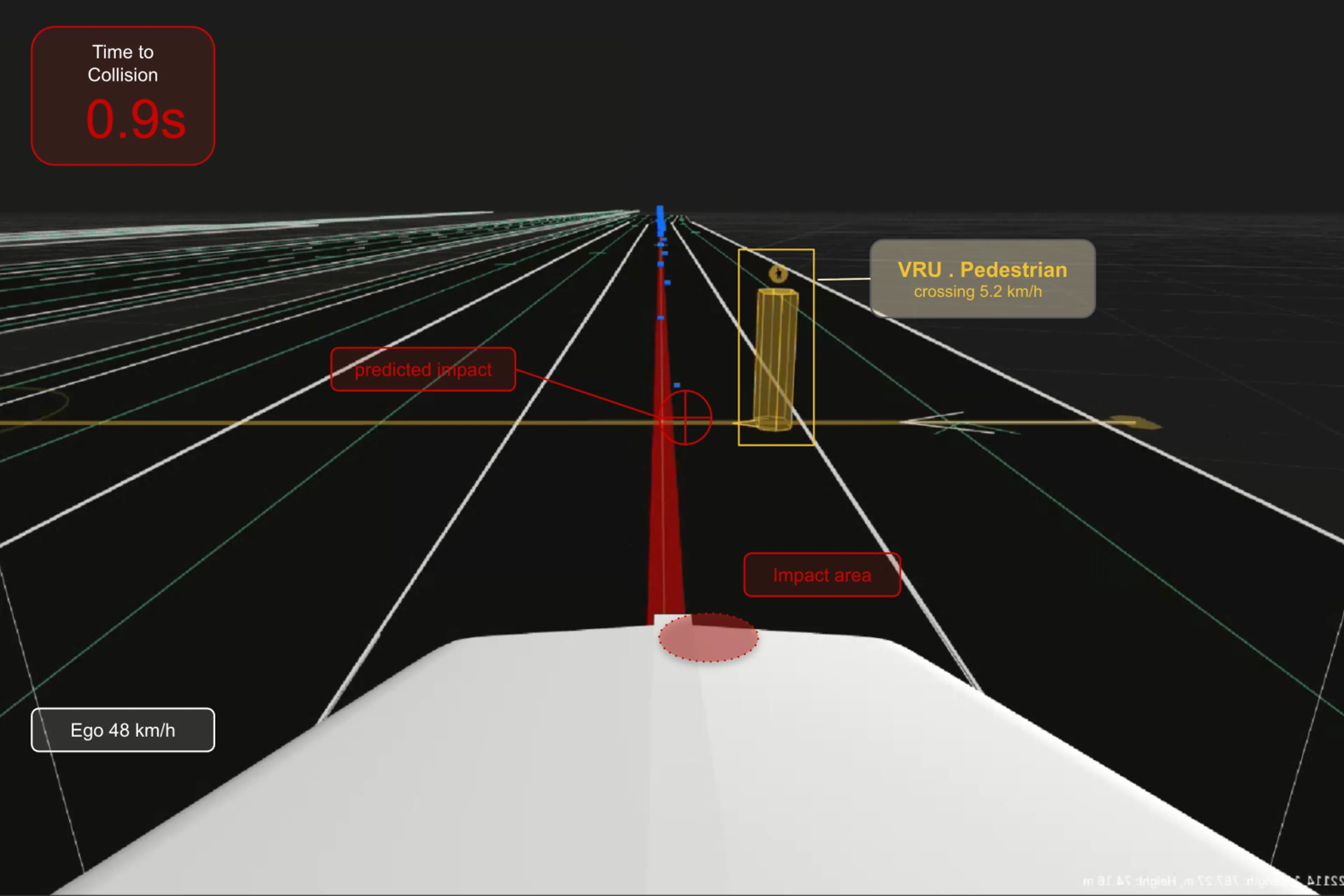
Figure 1: Testing perception system on synthetic data
Creating Synthetic 3D Environments
Many approaches for environment generation have been developed through decades of work in the entertainment industry. However, there are several key differences between AV and entertainment environments. While both usually require photorealism, AV environments need to be created cheaply and in days (instead of months for entertainment), need to be extremely realistic (both to the human eye and to sensors), should be capable of being varied at runtime, and must be large enough to support many tests.
Traditionally, these environments would be hand-crafted where a 3D artist creates a number of assets and places them in the world. This method yields photoreal-looking results and makes for great demonstrations. However, due to the manual nature of this process, it does not scale to producing locations across the globe or yield the sheer size and number of environments required for AV testing. This is where the usefulness of simulated environments typically becomes limited.
Another approach is using scans of the real world which ensures a one-to-one match with the real data. The drawback of this approach is that the real data used often has many flaws. Because the lighting is baked in and there is no real material on the surface, it causes the camera and Lidar returns to be approximated at best. Furthermore, it may have holes, incorrect annotations, and moving agents in the environment that should be removed. It is also extremely storage and compute-intensive and can only generate areas that are encountered in real life.
A relatively new approach is to create worlds based on a procedural pipeline. In this approach, large environments and cities could be generated quickly using various types of inputs, resulting in a world that is generated mathematically (Figure 2). It also allows prescribing many different variations to an environment to prevent overfitting. Parameters such as time of the day or the weather could be changed while maintaining pixel accurate annotations. Overall, a new map could be made in a fraction of time it would take to craft by hand. The challenge with this approach is to ensure robust creation of real world features without manual tweaking.
Figure 2: Synthetically generated high fidelity buildings
Accurately Modeling Sensors
Synthetic data generation utilizes the environment created in the first step as input to the underlying sensor model. These sensor models must be capable of replicating detailed processes such as depth estimators in Lidar, Digital Beam Forming (DBF) characteristics in Radar, and noise sources in cameras while being performant enough to feed low latency HIL or data hungry training applications.
While it may appear daunting to consider that there exists hundreds or thousands of variations/topologies a sensor could take, all of them must ultimately obey the same fundamental principles of energy transfer and information theory. A carefully designed sensor modeling framework could yield a flexible structure that is capable of fitting to many variations. This underlying philosophy originates from the aim to bring electro-optical and signal processing system design tools out of the sensor design world and into the perception simulation space.
Even with a theoretically well-defined system though, the value of the model goes only so far as its ability to capture the real counterpart. The degree of correlation between real and synthetic depends heavily on use cases. While a data sheet may be sufficient for a simple use case, statistical quantification of various intrinsics may be necessary for others. This generally consists of a combination of controlled lab and field data collection experiments for determining specific sensor properties. In short, sensor modeling (and the fidelity of) could be thought of as the science of taking something perfect and making it worse in very intentional ways.
Figure 3: Modeling 128-beam, mechanically rotating Lidar system
Performance and Repeatability of Synthetic Data
Two additional areas that limit the fundamental usability of synthetic data are performance and repeatability. In many ways, the biggest challenge to sensor modeling for autonomous applications is the fidelity that could be achieved within the limitations of real-time processing. Fidelity and performance are also tightly coupled with the scalability of synthetic sensor generation. In order to facilitate a scalable solution, the use of parallel resource utilization is increasingly important.
This coordination of multiple resources naturally leads to the question of repeatability. In order for a parallelization effort to be successful, it is necessary to have parity between both concurrent and non-concurrent simulations. Determinism is a key component which enables a perception engineer to test changes to their algorithms in isolation while also still utilizing variation simulation provides.
Sensor Simulation: Tailoring to Individual Cases
Once the methods for developing environments and sensors have been created, the next challenge is to assess if the synthetic data that is produced is sufficient for the use cases. Depending on the maturity of the perception software, the use cases could range from checking sensor placement using synthetic data to testing final production systems for deployment.
Each use case requires different levels of model fidelity, which drive the verification and validation process. Verification describes the process for determining if the simulated model conforms to the original design spec (Did we build what we intended to?) This also ties into determinism (Are the results produced by a model repeatable under the same conditions every time?) In contrast, validation looks to the requirements of an end user to determine if the model meets the needs of the application. In some cases, it might be acceptable for the synthetic sensor model to be a rough approximation of the underlying physics. However, production testing use cases require synthetic sensor models that are extensively tested in both indoor and outdoor lab environments to meet precise uncertainty levels.
The evaluation of sensor models is also broader than comparison at the sensor output level. While this holds true for many perception-focused autonomous driving applications, the end-user is also interested in the performance of their perception model metrics on the synthetic versus real data. These models could be computer vision-based or built using different Machine Learning and Deep Learning methodologies. This is where the sources of uncertainties are unknown if confidence in the synthetic sensor model has not been sufficiently established.
Applied Intuition’s Approach
Applied Intuition has developed a tool from the ground up for simulating perception systems that address the challenges outlined in the article above. It includes workflows for creating large scale environments, developing multi-fidelity sensors, and an effective process for use case-based validation. The environment generation is done through a unique procedural pipeline that is flexible across geographic domains, autonomy applications, and data input sources. These capabilities have been developed by working with top AV developers worldwide across a variety of perception applications. We will continue to invest heavily in this technology to further push the envelope on what’s possible with synthetic perception simulation.