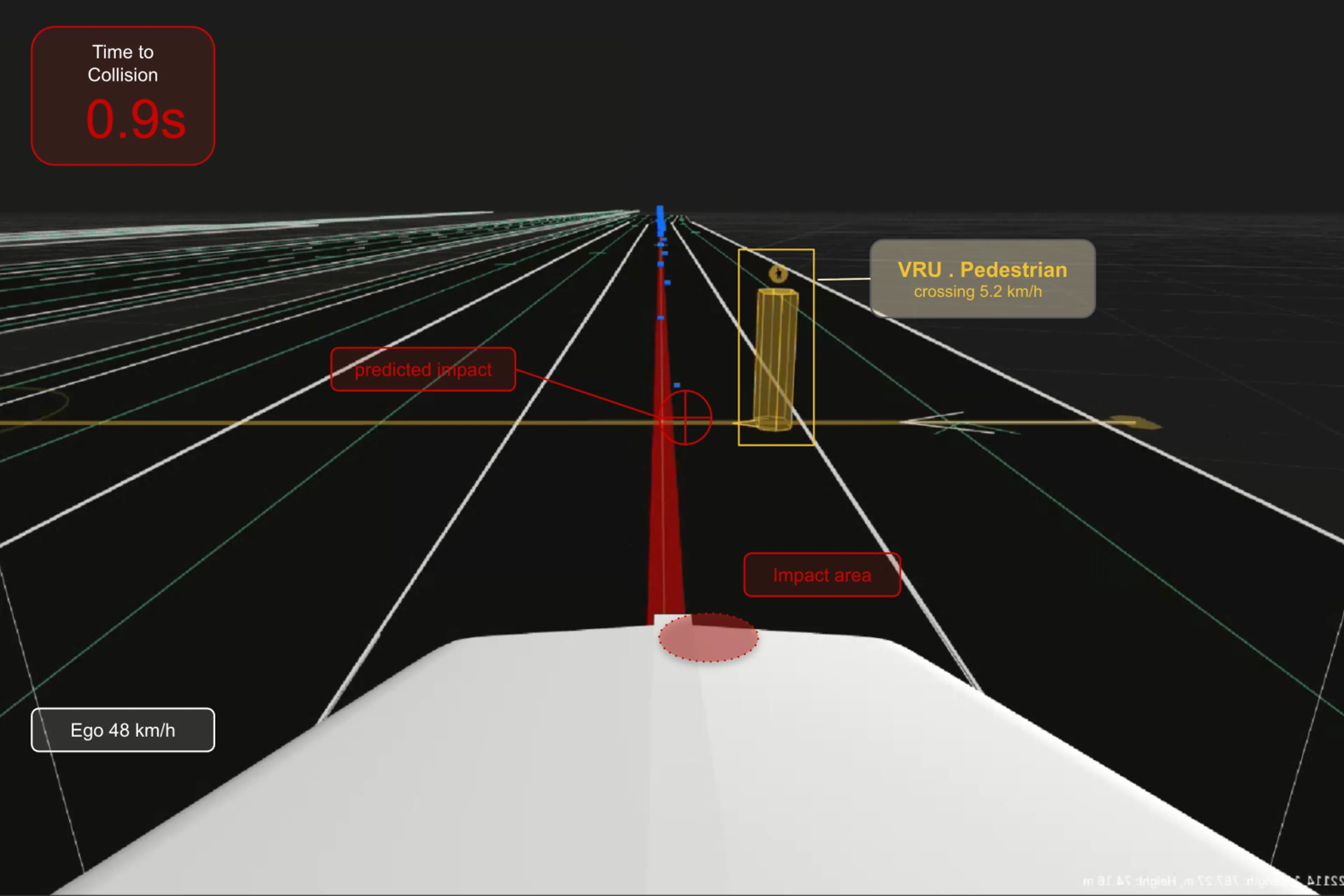
How Quality Metrics Reduced AEB Resimulation Failures from 73% to 3%
The data was already there — it just looked unusable. Here's how quality metrics revealed it, reducing resimulation failures from 73% to 3% and unlocking 87x more valid AEB test data.
Holger Helmich, Noam Rand, Andi Tamke • April 14, 2026 • 9 min read
Your team has done everything right. Vehicles are recording fleet data at scale. Logs are uploaded. You trigger a batch of AEB open-loop resimulation jobs, and more than 70% of them crash. This is not a hypothetical. It is a failure rate we see routinely in fleet data pipelines before quality metrics are in place.
The Hidden Cost of Bad Data in Resimulation Pipelines
Most data pipelines rest on a simple assumption: If the log uploaded successfully, it is simulation-ready. File present, correct size, no transfer errors.
The reality is more fragile. A log that passes every upload validation check can still be missing critical signal data in specific time windows—invisible until a GPU job starts executing and the simulation stack fails looking for data that isn't there. This is not a niche edge case; it is a structural property of how in-vehicle recording systems work. And bad data doesn't fail once; it compounds at every downstream stage:
Storage: Unusable data occupies cloud storage indefinitely, indistinguishable from valid data
Compute: GPU jobs consume queue slots and run for minutes before crashing
Engineering: Developers investigate what look like simulation stack bugs, only to find data problems
Retry: The cycle repeats on the same fundamentally broken data
At fleet scale, this cascade is expensive. Wasted GPU compute, redundant storage, and engineering debug cycles add up to significant annual cost—not counting the opportunity cost of valid test data buried in logs that appeared unusable.
ADAS sensor data entering the quality validation pipeline
Three Failure Modes That Crash Resimulation
Drive logs fail silently because recorders and downstream safety validation have different definitions of completeness. A recorder considers a log complete when all files are written and transferred. A simulation stack could, in principle, be made robust enough to tolerate gaps in its input data. But for safety-critical functions like AEB, that would mean masking degraded input and trusting the stack to compensate—which is fundamentally the wrong approach. In active safety, the correct principle is to ensure quality input data and tolerate gaps only where there is a defined, validated fallback strategy (for example, compensating for a tunnel GPS outage using odometry and map matching until the signal recovers). Gaps without such a strategy are not acceptable simulation input. This distinction shows up in three consistent failure patterns that affect any fleet data pipeline.
Failure mode 1: Signal gaps in vehicle bus data
Drive-by-wire feedback publishes at 50 Hz and provides vehicle dynamics signals—the most critical being longitudinal velocity, which the AEB function uses to compute time-to-collision and determine whether emergency braking is warranted. Additional signals such as yaw rate and steering angle feed path prediction for target selection. In active safety, missing this feedback for even seconds, without an alternative backup path, is not acceptable. There is no safe way to evaluate AEB behavior when the signals driving its braking decision are absent. In typical fleet data, CAN signal gaps spanning tens of minutes are observed in logs where cameras and radar show no interruption. From a file-level perspective, the log looks fine. The simulation correctly refuses to produce results from this input—it times out rather than generating an untrustworthy evaluation. The segment is unusable for the entire duration of the gap.
Failure mode 2: Empty segments at log boundaries and operational pauses
Gaps with zero messages appear in three situations: at the start of a log, where sensors initialize after the recorder begins writing; at the end, during shutdown sequences; and mid-log, when drivers pause between drives and certain topics go silent while the recording system continues running. In all three cases, the affected segments contain no meaningful driving scenario. A standard quality metric—measuring maximum inter-message time delta—reports 0.0 for a completely empty segment, which passes most filter thresholds. Empty data flows into resimulation and fails. Any quality filtering system must detect and exclude these empty windows explicitly, regardless of where they occur in the log.
Failure mode 3: Missing required topics
AEB resimulation requires a minimum set of topics to be present and continuous simultaneously—in this case, ego pose, vehicle dynamics, object detections, and lane lines. As the active safety sensor suite matures, this set grows; radar channels, for example, are part of the target AEB configuration. Quality metrics may exist for cameras in a pipeline, but not necessarily for AEB-critical vehicle bus or radar signals. A single missing topic for a single segment means the simulation cannot produce a valid evaluation. The quality metrics framework must be extensible so that new sensor modalities are covered by configuration, not infrastructure changes. Without metrics covering all currently required topics, those segments cannot be filtered before triggering.
What a Quality-Aware Pipeline Looks Like
Solving these failure modes means shifting quality assessment from resim trigger time back to ingestion time. The core architecture: compute quality metrics per fixed-size segment (30 seconds) during ingestion, store them in a queryable table, and query them before triggering any downstream workflow.
Two metrics per topic cover all three failure modes: message count (is data present?) and maximum inter-message time delta (is data continuous?). Segment filtering then queries those metrics against workflow-specific thresholds. AEB resim requires max_gap ≤ 1.0s AND message_count > 0 across all four required topics simultaneously. Different workflows (objectsim, training data extraction) use different topic sets and thresholds against the same stored metrics. No re-ingestion required.
Two additional steps turn filtered segments into a runnable batch. Chain detection groups consecutive quality-passing segments into continuous windows and splits long chains to avoid job timeouts. Interval-based recovery identifies valid data on either side of a gap rather than rejecting the whole log.
Quality filter failure rates by signal category over time
Applied Intuition’s Implementation: Data Engine
Applied Intuition's Data Engine implements this architecture as part of an end-to-end platform spanning fleet data collection, ingestion, enrichment, discovery, simulation, and validation. Quality metrics are computed during the post-upload ingestion pipeline via Spark jobs and stored in Hudi tables queryable via Trino—not a separate tool bolted on, but part of the same platform that triggers simulation.
In this case study, a single engineer added four new AEB-specific metrics to an existing set of 47-plus sensor metrics, covering the vehicle bus topics the previous set didn't include. New metrics are a configuration addition, not an infrastructure change.
With metrics in place, a single CLI command queries the metrics table, identifies valid windows, builds batch-triggerable chains, and submits the job. The command supports configurable thresholds, duration limits, and dry-run mode. When a new quality issue surfaces, a single engineer can trace it to ingestion, add a metric, backfill historical data, and deploy a fix in days. In a fragmented multi-vendor toolchain, the same cycle typically takes months of cross-team escalation.
Applied Intuition's closed-loop Data Engine pipeline
Results
Sample batch run
The headline numbers reflect both quality filtering and interval-based recovery applied to a single representative batch run from a bounded collection window. The resim failure rate dropped from over 70% to under 3%, and the volume of valid test data accessible from the same set of recorded drives increased by 87x. The improvement came not from collecting more drives, but from correctly identifying what was already there.
Scaled to a single car setup
When the same quality-aware workflow is applied across all collected data for a single car setup within a defined collection window the results demonstrate how this approach scales. The result is a 74% utilization rate: Nearly three quarters of raw collected time is directly usable for AEB resimulation after quality filtering.
Metric
Value
Total collected hours
>200 h
Valid hours for AEB open-loop resimulation
>170 h
Data utilization rate
74%
Continuous Monitoring: Closing the Feedback Loop
A quality filtering workflow that runs once solves the immediate problem. A monitoring layer that runs continuously prevents the next class of problems from reaching simulation at all.
Data Engine surfaces two purpose-specific dashboards for this workflow. The AEB Testing Log Quality Monitoring dashboard provides a per-topic coverage heatmap across fleet logs, gap detection, and fleet-wide quality trends updated at ingestion time. The AEB False Positive Monitoring dashboard tracks FP rates per 1,000 km from resimulation results, connecting data quality back to driving function confidence.
Critically, quality trends are reported back to drive collection and stack performance teams before GPU jobs are triggered, not after they crash. The same infrastructure that fixed the high failure rate generates the continuous signal needed to prevent the next one.
From Toolchain Gap to Single-Engineer Fix
A resimulation failure rate above 70% looks like a simulation problem. What it actually was: a toolchain gap — the space between ingestion and simulation triggering where nobody was checking whether data met the requirements of the workflow. In a fragmented multi-vendor toolchain, closing that gap takes weeks of cross-functional coordination. In an integrated platform, one engineer closes it in days.
The fix also revealed 87 times more valid AEB test data already sitting in the fleet. And when scaled to a full car setup collection window, 74% of all recorded hours proved directly usable for AEB open-loop resimulation. Reliable resimulation at scale isn't just about reducing failures: It's about making statistically meaningful ADAS validation possible with the data you already have.
That pattern has continued. The same workflow is now live across all drive data collected with an AEB-equipped setup, and LDW false positive monitoring is following the same path. Next, the same engineer and the same pipeline will extend coverage to ODD categories without any new infrastructure. One engineer configures the system and owns the full end-to-end false positive monitoring workflow for active safety, from ingestion to results.
If your team is facing high resimulation failure rates or suspects valid test data is being discarded in your existing drives, Data Engine's quality metrics and monitoring are worth a close look. Request a demo or reach out to the Applied Intuition team to benchmark your pipeline against the numbers in this post.
Holger Helmich
Solution Engineer
Holger Helmich is a Solution Engineer at Applied Intuition with more than 15 years of experience designing software solutions in close collaboration with European car OEMs. He holds a Master's in 3D Computer Vision and Image Recognition from Hochschule München and specializes in simulation tools for the development and validation of SAE Level 3+ autonomous driving functions.
Noam Rand
Product Manager
Noam Rand is a Product Manager at Applied Intuition building data and simulation platforms for physical AI across domains. He brings a background spanning autonomy and robotics, having previously founded and led a robotics startup and served in a special operations technology unit in Israeli Military Intelligence.
Andi Tamke
Software Engineer
Andi Tamke is a Software Engineer at Applied Intuition with nearly two decades of experience in behavior planning, environment modeling, and situation assessment for ADAS and autonomous driving systems. He holds a PhD in Computer Science from the University of Stuttgart.