NoRD: A Data-Efficient Vision-Language-Action Model that Drives without Reasoning
NoRD eliminates reasoning overhead in autonomous driving, matching top benchmarks with less data by fixing a key flaw in reinforcement learning optimization
Current Vision-Language-Action (VLA) models for autonomous driving rely on two primary dependencies: massive dataset collection and dense reasoning annotations. While such models achieve high performance, they introduce significant data costs, computational overhead, and high inference latencies, making them impractical for real-world deployment. In this work, we challenge both of these dependencies with NoRD: No Reasoning for Driving. We identify that the performance gap in data-efficient, reasoning-free models is not due to a lack of reasoning or deficiency of data, but rather difficulty bias. This bias occurs during Reinforcement Learning optimization of a weak policy with sparse driving rewards, causing the model to ignore complex, difficult maneuvers in favor of learning from easy samples. By using Dr. GRPO to mitigate the difficulty bias, NoRD achieves competitive performance on Waymo and NAVSIM benchmarks using 3x fewer tokens and 60% less data than reasoning-heavy baselines. NoRD demonstrates that by simple modifications to the VLA optimization step, we can achieve high performance with a fraction of the training data and no reasoning overhead for more efficient autonomous systems.
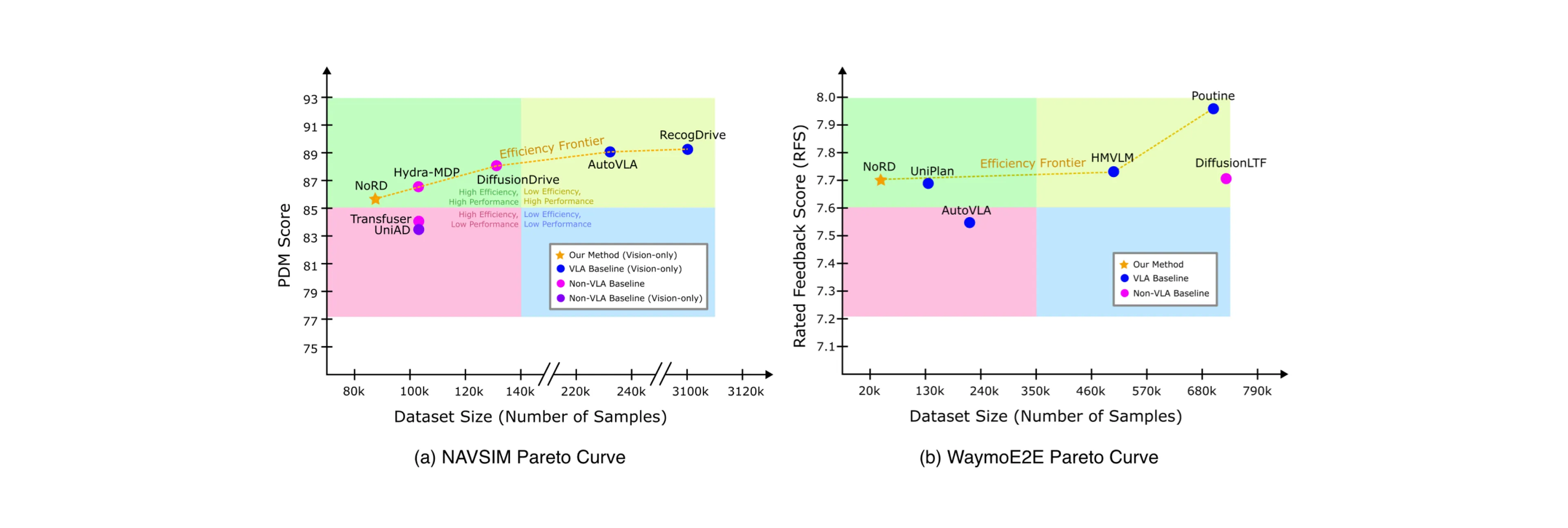
Vision-Language-Action (VLA) models represent a promising frontier for autonomous driving, particularly in resolving "long-tail" scenarios. These models typically reason through a scene, generating internal text traces before deciding on an action.
However, this mechanism of “thinking out loud” introduces two significant bottlenecks:
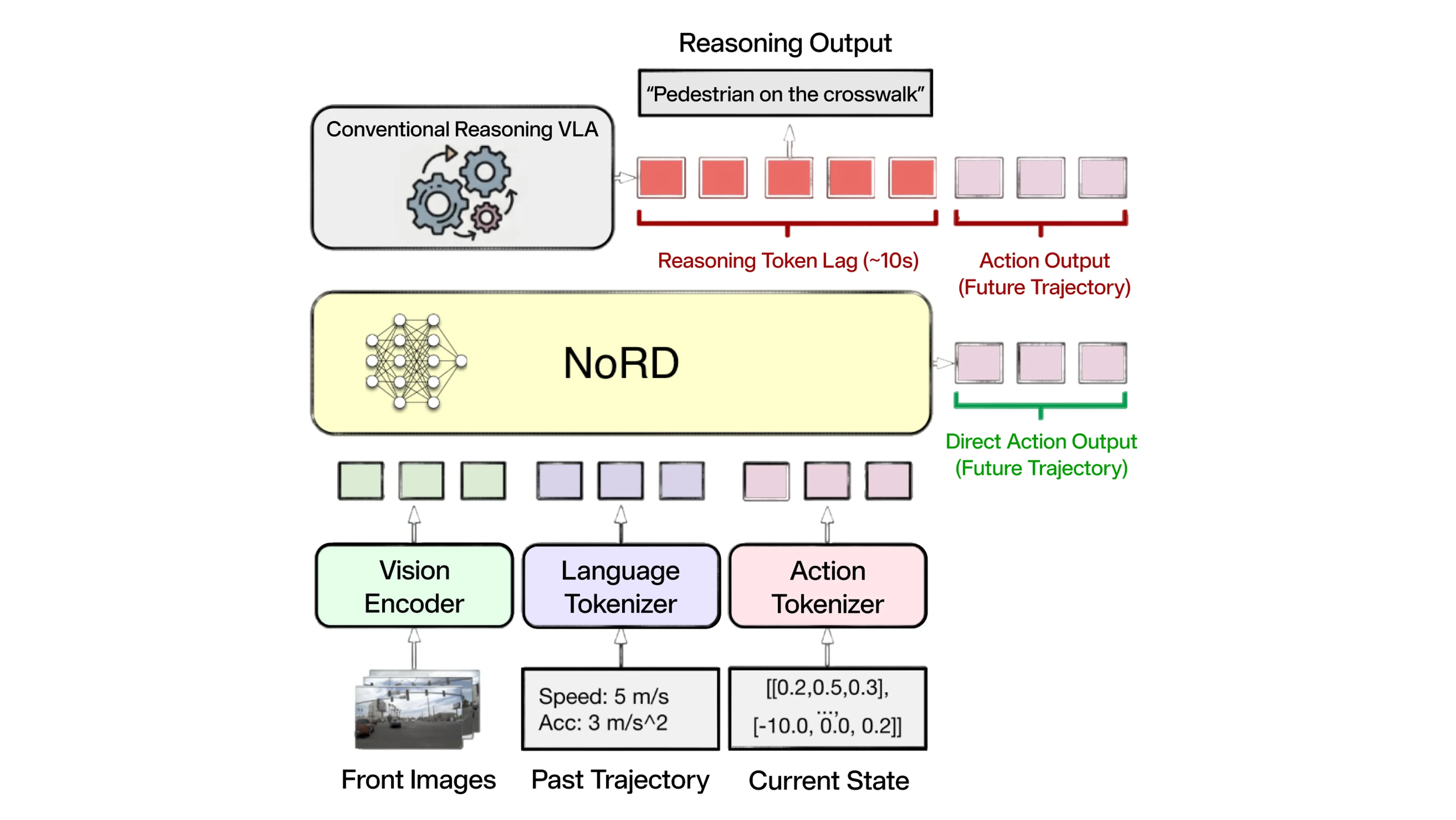
To address this, we propose NoRD (No Reasoning for Driving). NoRD bypasses intermediate text generation entirely, mapping inputs directly to action. By leveraging the VLM’s internal spatial-temporal priors without the overhead"autoregressive tax" of reasoning tokens, NoRD maintains high-level understanding while reducing latency to be under a fraction of a second.
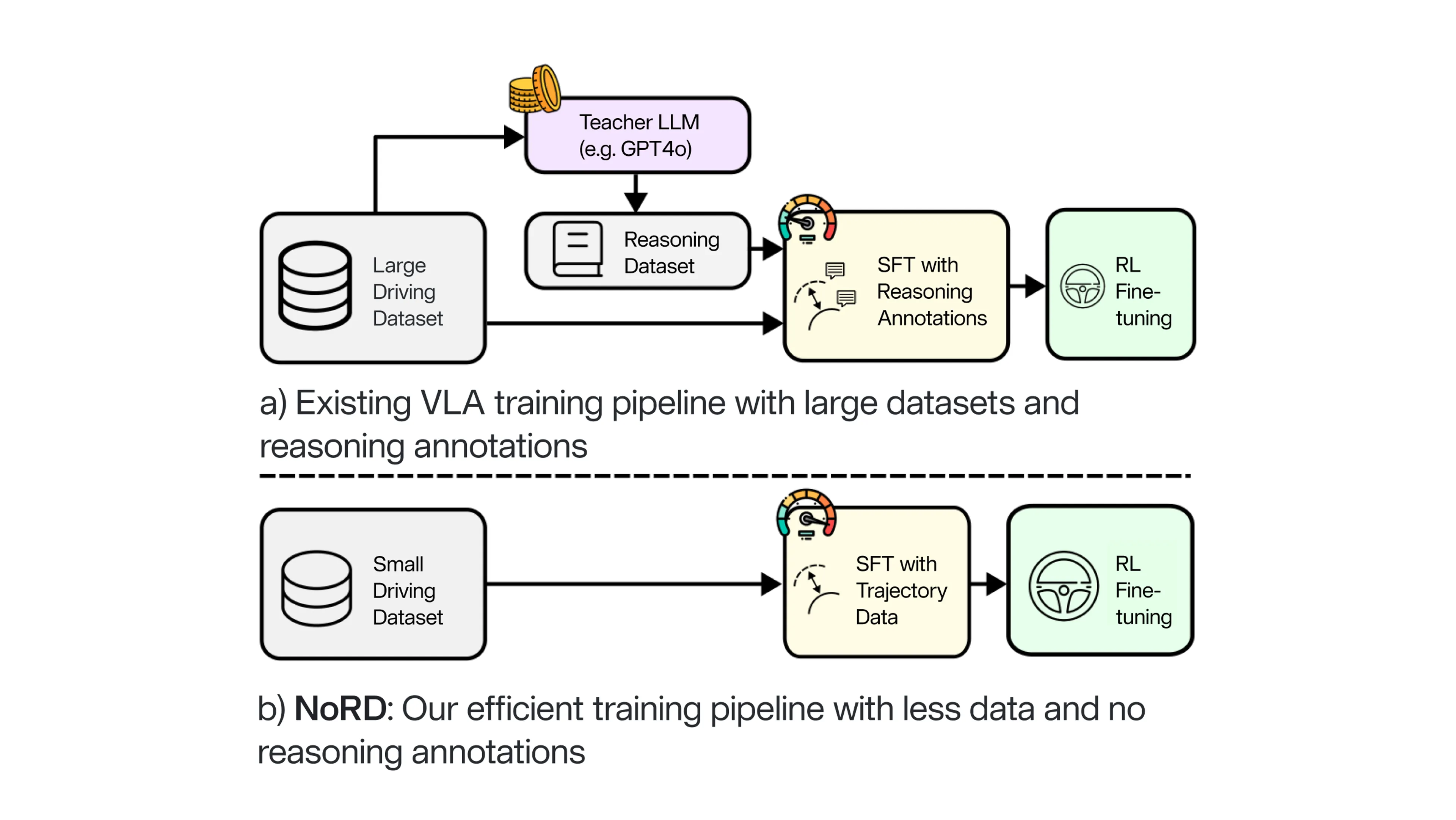
To achieve state-of-the-art performance, conventional VLA pipelines rely on a complex, data-heavy architecture. This traditional approach involves several resource-intensive stages:
While effective, this pipeline is inherently bottlenecked by the need for expensive teacher models and vast amounts of driving data.
In contrast, NoRD follows a simpler and more efficient alternative. By reducing the data removing the requirement for intermediate reasoning, we streamline the process significantly:
By eliminating the reasoning overhead, NoRD creates a recipe for high-performance autonomous driving that is not only cheaper to train but also faster to develop and deploy.
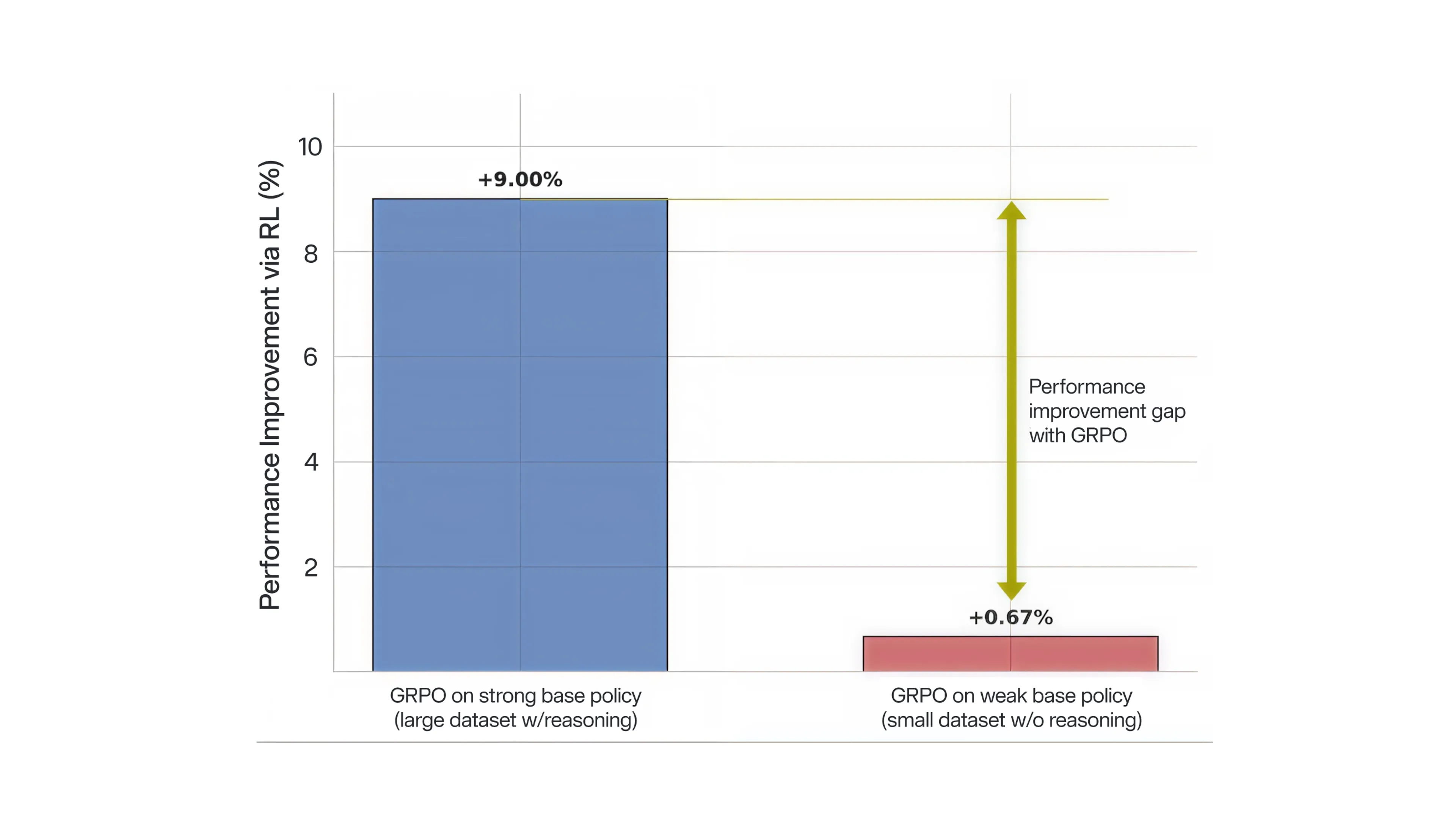
While Group Relative Policy Optimization (GRPO) is commonly used in RL fine tuning of most existing reasoning-based VLAs, we observed that it produces a negligible 0.67% improvement when applied to a data-efficient, non-reasoning (weak) SFT base policy. This stands in contrast to the 9% boost observed in prior works (e.g., AutoVLA) using massive datasets and explicit reasoning traces. Rather than attributing this failure to an inherent limitation of weak policies, we explore an alternate hypothesis: that standard RL optimization is fundamentally ill equipped to train reasoning-free and data-efficient policies. This motivates our investigation into difficulty bias as a primary bottleneck to improvement.
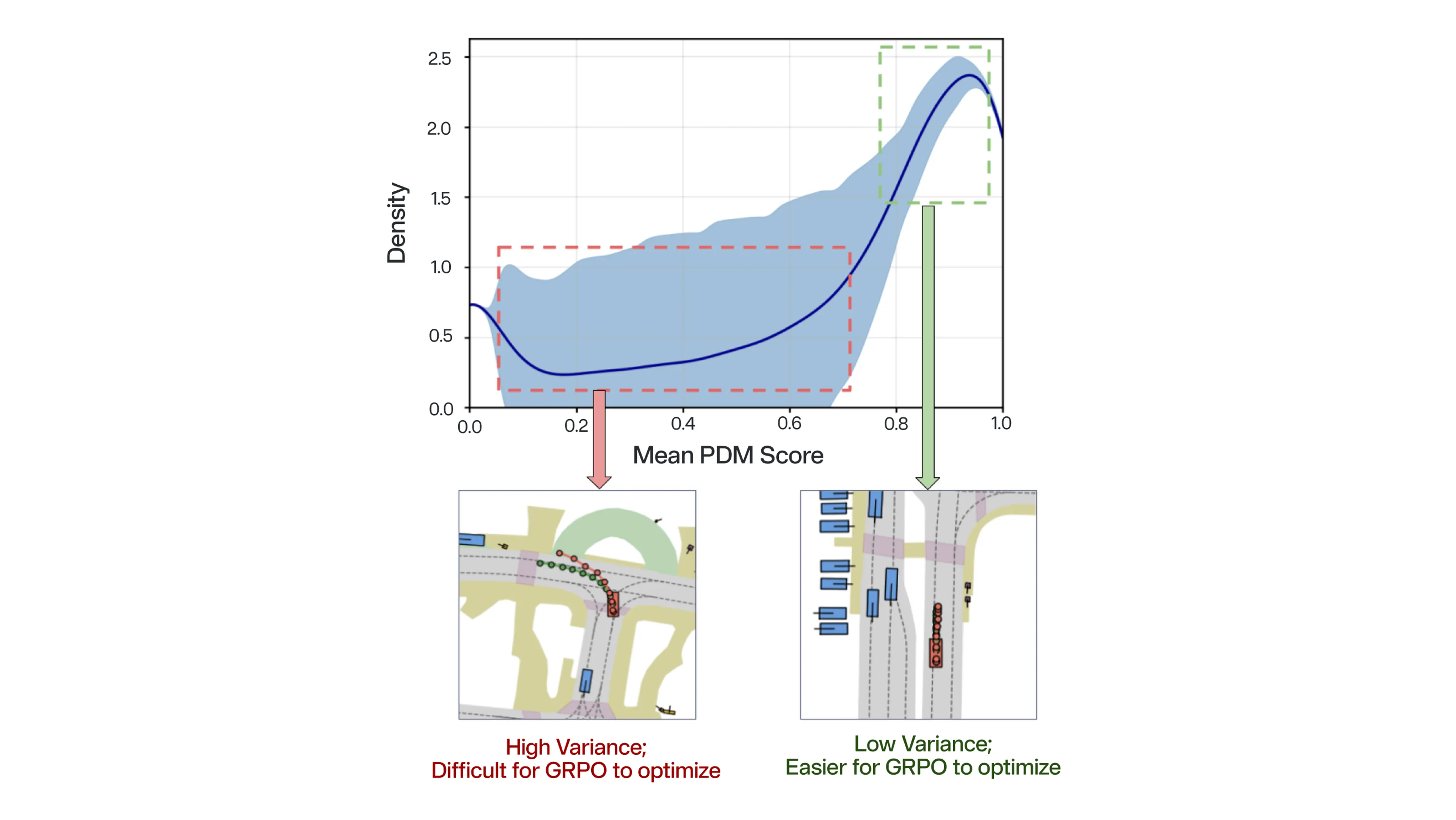
To validate our hypothesis that the performance bottleneck lies within the optimization process rather than the model’s inherent capacity, we analyze the density of mean PDM (Predictive Driver Model) scores produced by the weak base policy across the NAVSIM dataset. This reveals two distinct regimes:
In standard GRPO, gradients are averaged across groups. Hence, the model spends its learning budget on easy scenarios it has already mastered, while the suppressed signals from hard scenarios fail to drive policy improvement. We interpret this failure as a form of difficulty bias in GRPO.
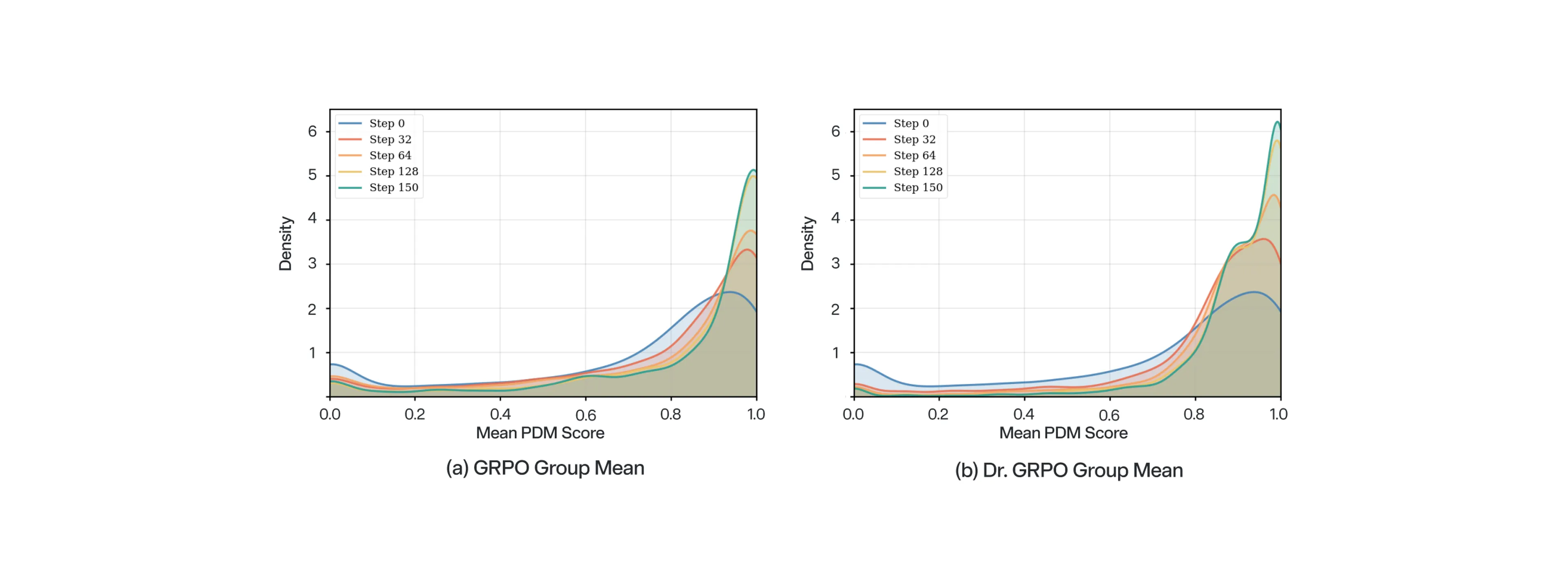
To overcome the limitations of standard RL, we employ Dr. GRPO as a drop-in replacement for fine-tuning our weak base policy. By rebalancing the optimization to be less sensitive to the group variance, Dr. GRPO enables the model to optimize in our complex reward landscape. Notably, it converts our previous 0.67% gain with GRPO into an 11.68% gain, demonstrating a much more robust shift in the optimization curves toward high-performance scores. This allows NoRD to learn complex driving maneuvers that were previously unattainable through standard GRPO.
NoRD demonstrates robust spatial-temporal understanding across diverse long-tail scenarios, executing complex maneuvers.

Driving in Rain

Construction zones

Turning in traffic

Traffic light understanding

Extreme light transitions

Stable following

Making an unprotected turn

Dense traffic
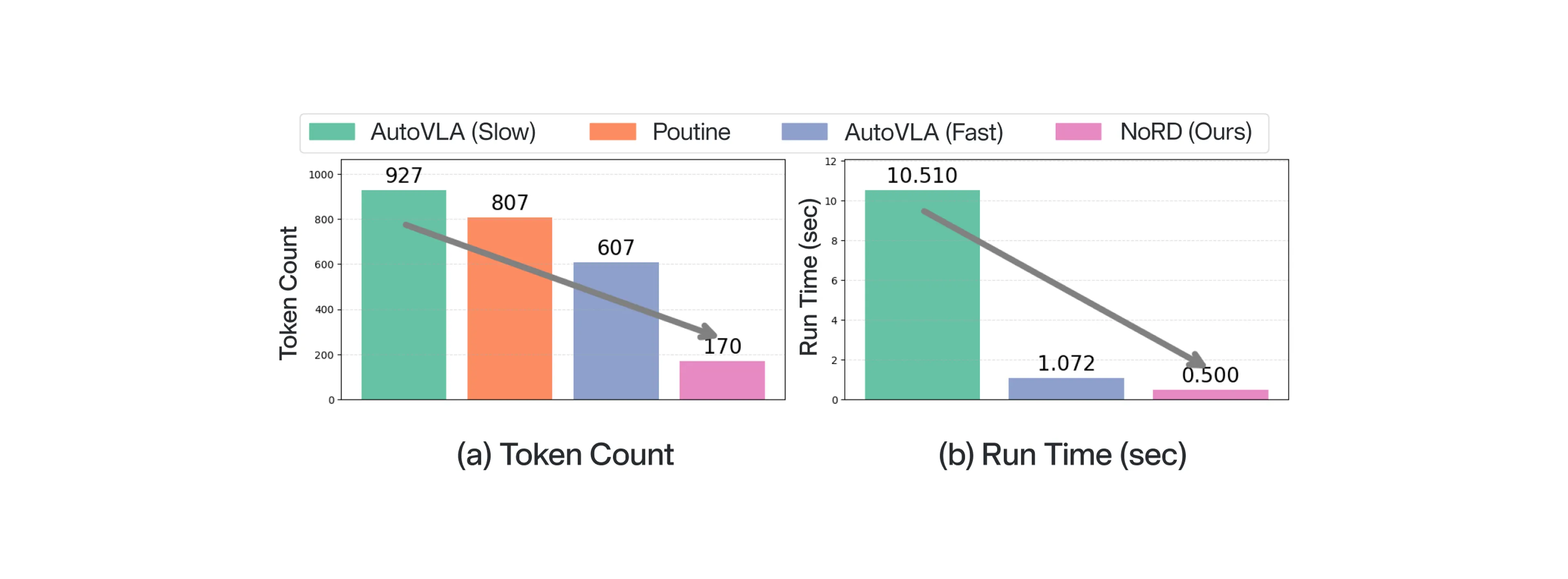
By bypassing intermediate reasoning tokens, NoRD achieves massive efficiency gains, significantly reducing token counts and run time over reasoning VLAs
While NoRD navigates a wide variety of traffic scenarios effectively, it is not without limitations. Our analysis of the model’s performance reveals specific failure modes, such as in making wider turns than necessary and multi-agent interaction, that provide avenues for future improvement.

Aggressive maneuvering

Blindness to rear traffic

Conservative stops
@inproceedings{rawal2026nord,
title={NoRD: A Data-Efficient Vision-Language-Action Model that Drives without Reasoning},
author={Rawal, Ishaan and Gupta, Shubh and Hu, Yihan and Zhan, Wei},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}Research Scientist
Shubh Gupta is a Research Scientist at Applied Intuition focused on generative AI and autonomous driving. He holds a PhD in Electrical Engineering from Stanford University, where his research centered on high-integrity localization for autonomous vehicles. While at Stanford he conducted postdoctoral research on neural mapping and navigation systems.
Research Intern
Ishaan Rawal was a Research Intern at Applied Intuition working on vision-language-action model post-training for autonomous driving. He holds a Master's degree in Computer Science from Texas A&M University and a BE in Computer Science from Birla Institute of Technology and Science, Pilani.

