NoRD: 推論なしで走行する、データ効率に優れた視覚と言語に基づく行動生成モデル
NoRD は、強化学習の最適化における重要な欠陥を解消することで、自動運転における推論オーバーヘッドを排除し、より少ないデータで最高水準のベンチマーク性能を実現します
現在の自動運転向け VLA (Vision-Language-Action) モデルは、大規模なデータセットの収集と、高密度の推論アノテーションという 2 つの要素に大きく依存しています。こうしたモデルは高い性能を達成する一方で、データ コストが高く、計算オーバーヘッドと推論レイテンシも大きいため、実環境への展開には適していません。
本研究では、NoRD: No Reasoning for Driving によって、こうした 2 つの依存要素に挑みます。データ効率に優れ、推論を必要としないモデルに見られる性能差は、推論の欠如やデータの不足ではなく、難易度バイアスに起因することを明らかにしました。このバイアスは、走行に対する報酬が疎な状況で、性能の低いポリシーを強化学習によって最適化する際に生じます。その結果、モデルは容易なサンプルからの学習を優先し、複雑で難易度の高い運転操作を見落としてしまいます。
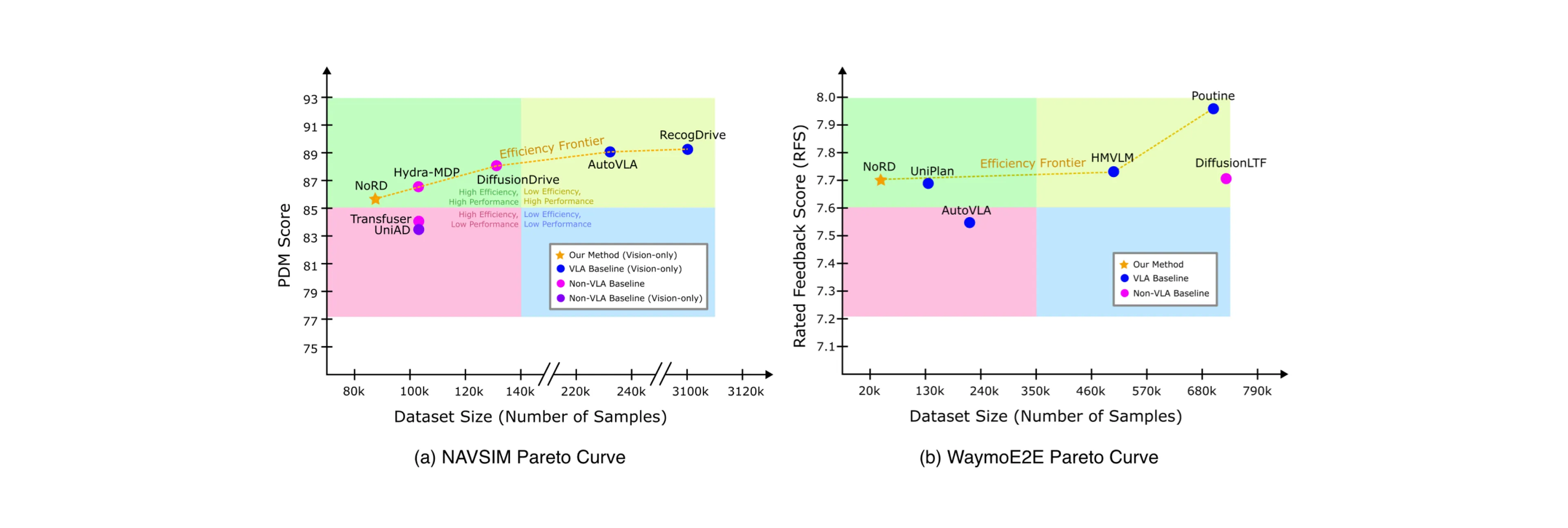
NoRD は、Dr. GRPO を用いて難易度バイアスを軽減することで、推論に大きく依存するベースラインと比べ、トークン数を 3 分の 1 に抑え、データ量を 60% 削減しながら、Waymo および NAVSIM ベンチマークで競争力のある性能を達成します。NoRD は、VLA モデルの最適化ステップにわずかな変更を加えるだけで、必要な学習データを大幅に削減し、推論に伴うオーバーヘッドなしで高い性能を実現する、より効率的な自動運転システムへの道筋を示しています。
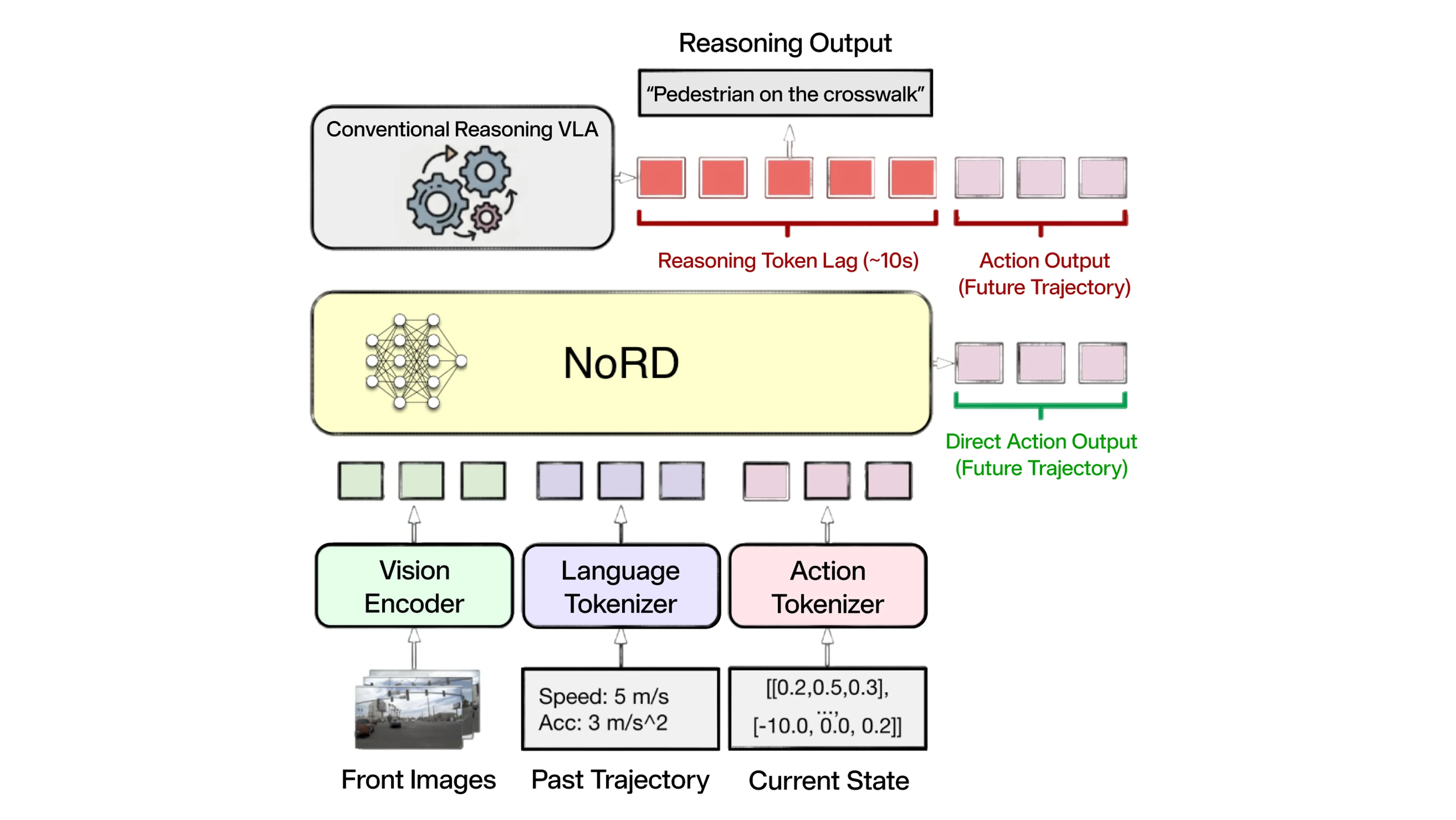
VLA (Vision-Language-Action) モデルは、特に「ロングテール」シナリオへの対応において、自動運転の新たな可能性を拓く有望なアプローチです。こうしたモデルは通常、シーンを分析して推論を行い、行動を決定する前に内部テキスト トレースを生成します。
しかし、この「思考の言語化」の仕組みには、2 つの大きなボトルネックがあります:
この課題に対応するため、我々は NoRD (No Reasoning for Driving) を提案します。NoRD は中間テキストの生成を完全に省き、入力から行動を直接導き出します。視覚言語モデル (Vision-Language Model, VLM) が内部的に持つ時空間に関する事前知識を活用し、推論トークンの自己回帰的な生成に伴う「自己回帰の負荷」を回避することで、高度な状況理解を維持しながら、レイテンシをわずか数分の 1 秒未満にまで低減します。
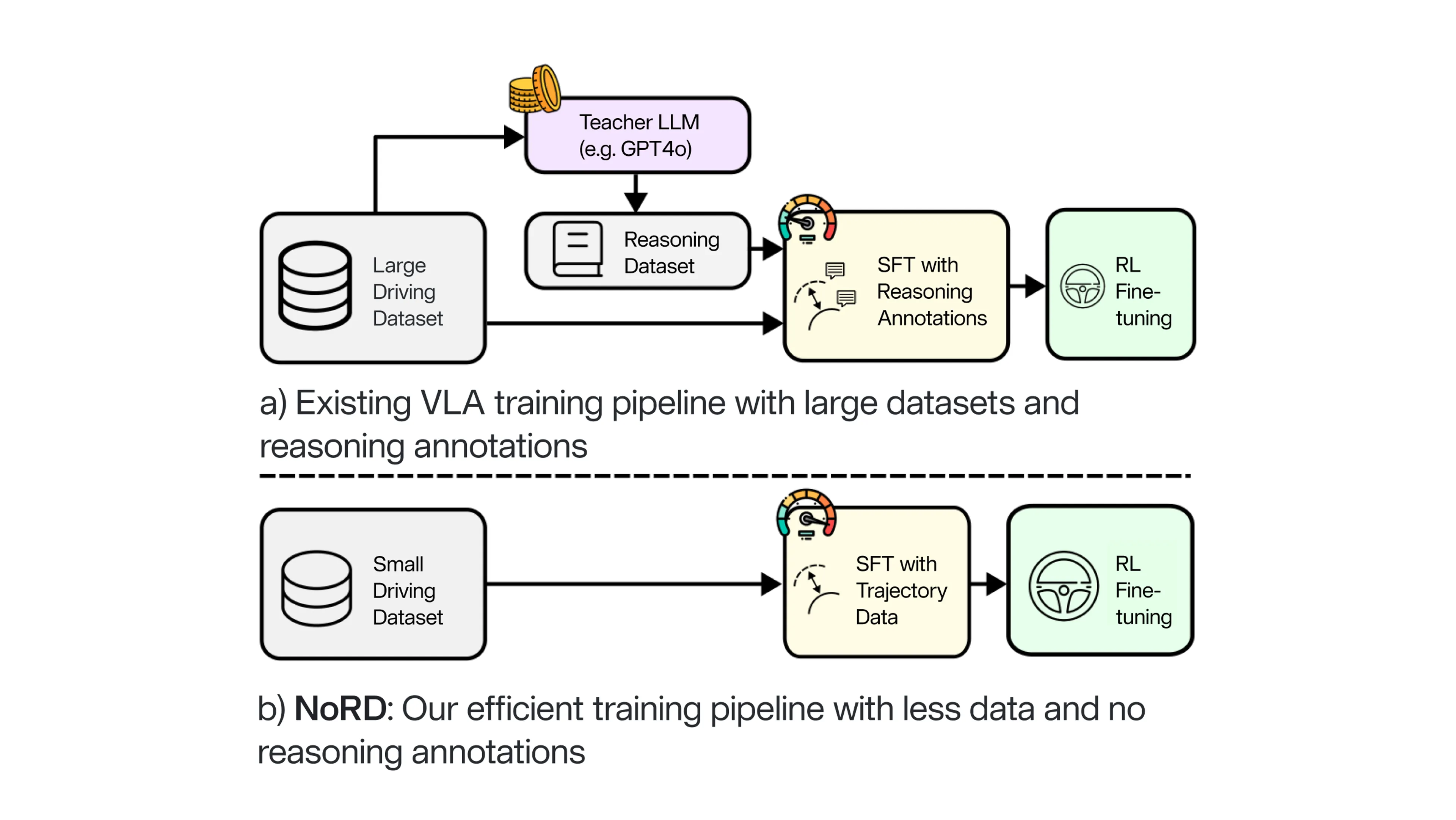
最高水準の性能を実現するため、従来の VLA パイプラインは、複雑で大量のデータを必要とするアーキテクチャに依存しています。このアプローチには、多くのリソースを必要とする複数のステップがあります:
このパイプラインは有効ではあるものの、高コストな教師モデルと膨大な走行データを必要とすることが、構造的なボトルネックとなっています。
対照的に、NoRD は、よりシンプルで効率的な代替アプローチを採用し、データ要件を削減するとともに中間推論を不要にすることで、プロセスを大幅に簡素化します:
推論に伴うオーバーヘッドをなくすことで、NoRD は、学習コストを抑え、開発から導入までを高速化する、高性能な自動運転のための手法を実現します。
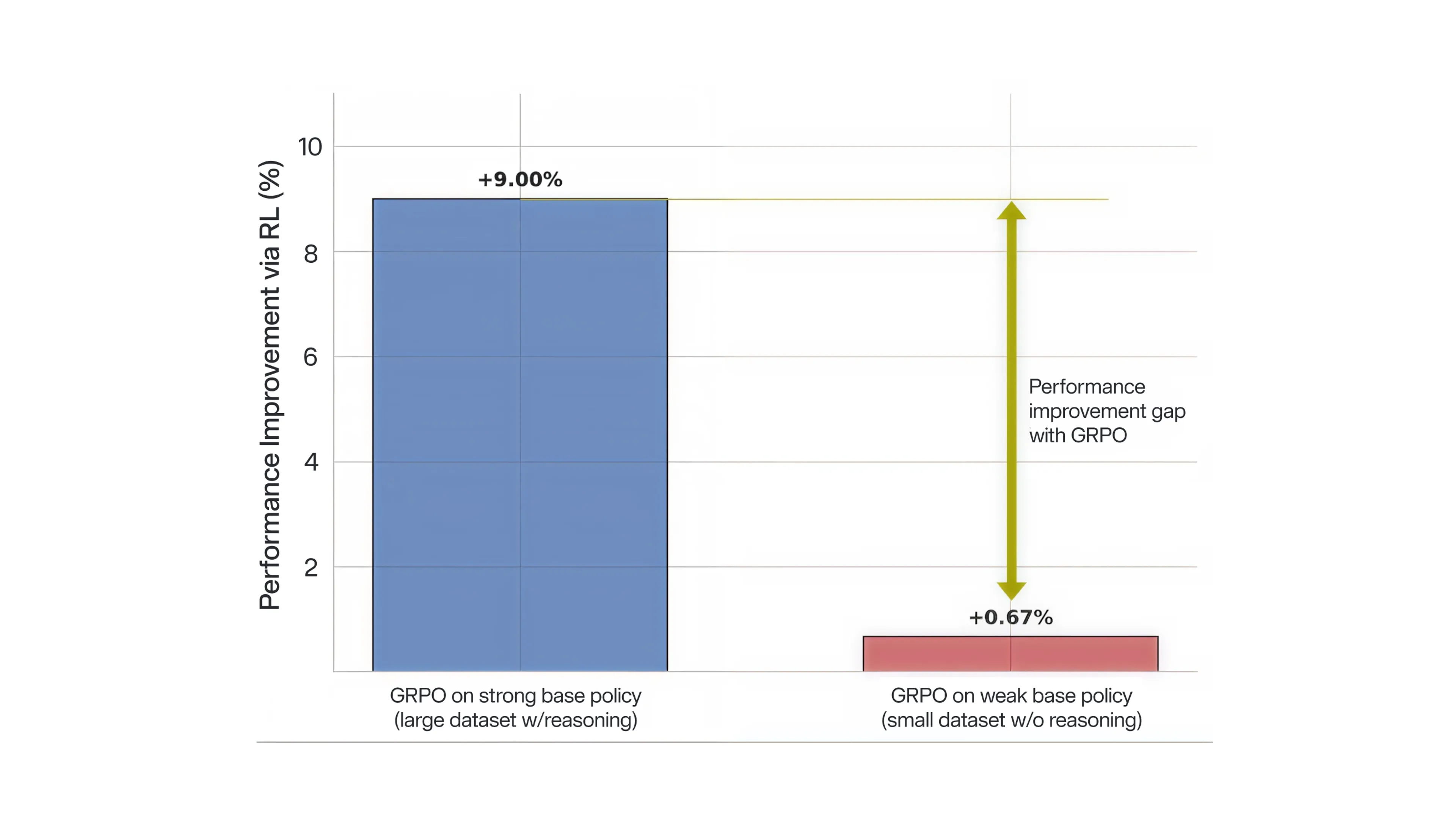
既存の推論ベース VLA の多くでは、RL ファインチューニングに GRPO (Group Relative Policy Optimization) が広く用いられています。しかし、データ効率に優れた推論なしの弱い SFT ベースポリシーに適用した場合、改善率はわずか 0.67% にとどまりました。これは、大規模なデータセットと明示的な推論トレースを用いる AutoVLA を含む先行研究で確認された 9% の性能向上とは対照的です。
我々は、この結果を弱いポリシーに内在する限界として捉えるのではなく、別の仮説を検討します。すなわち、標準的な RL 最適化は、推論を必要とせず、データ効率に優れたポリシーを学習するには根本的に不向きです。 この仮説を踏まえ、我々は性能向上の主なボトルネックとして 難易度バイアス に着目します。
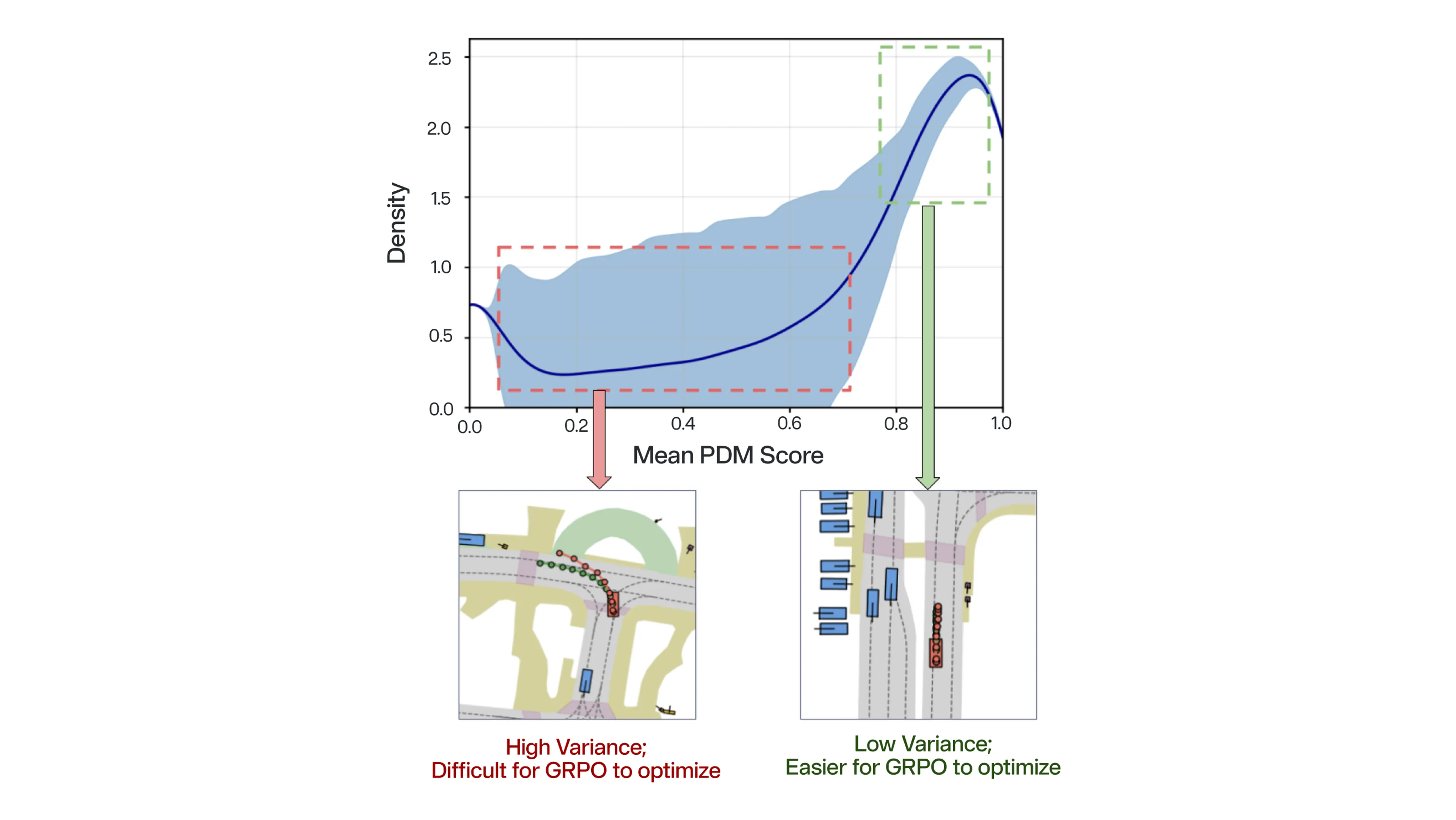
性能上のボトルネックがモデル固有の能力ではなく最適化プロセスにあるという仮説を検証するため、我々は NAVSIM データセット全体で弱いベースポリシーが出力する平均 PDM (Predictive Driver Model) スコアの密度分布を分析した結果、次の 2 つの異なる傾向が明らかになりました:
標準 GRPO では、勾配はグループ全体で平均化されます。その結果、モデルはすでに習得した容易なシナリオに学習リソースを費やす一方、困難なシナリオからの抑制されたシグナルは、ポリシーの改善を促すには至りません。我々は、この性能向上の停滞を、GRPO における難易度バイアスの表れと捉えています。
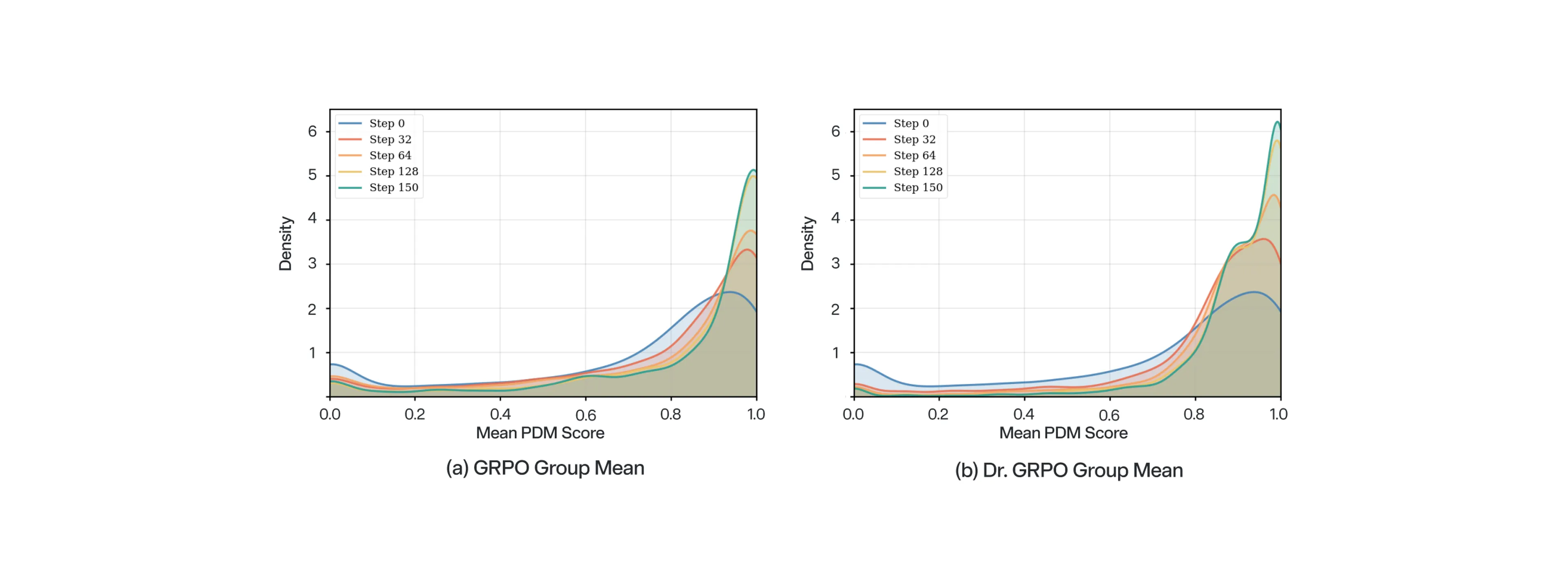
標準的な RL の限界を克服するため、我々は弱いベースポリシーのファインチューニングにおいて、標準 GRPO のドロップイン代替手法として Dr. GRPO を採用。グループ分散への感度を抑えるよう最適化のバランスを再調整することで、Dr. GRPO は複雑な報酬ランドスケープにおけるモデルの最適化を可能にします。
特筆すべきことに、Dr. GRPO は、GRPO による従来の 0.67% の性能向上を 11.68% へと引き上げ、最適化曲線が高性能スコアへ向けてより明確に移行したことを示しました。この改善により、NoRD は標準 GRPO ではこれまで習得できなかった複雑な走行操作を学習できます。
NoRD は、多様なロングテール シナリオにおいて堅牢な時空間理解を発揮し、複雑な走行操作を実行します。

雨天時の走行

工事区域での走行

交通のある場面での右左折

交通信号の理解

急激な明暗変化

安定した追従走行

保護信号なしの右左折

交通密度が高い状況
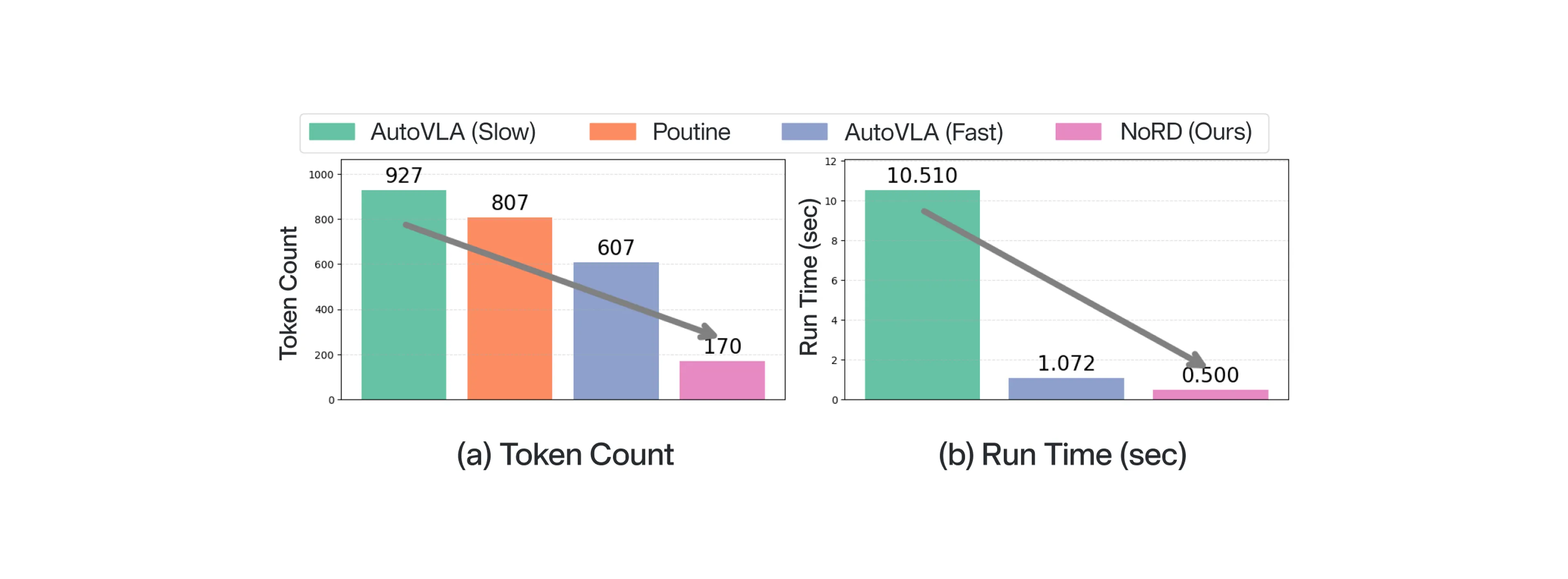
中間推論トークンを省くことで、NoRD は大幅な効率向上を実現し、推論ベース VLA と比べてトークン数と実行時間を大きく削減します。
NoRD は多様な交通シナリオに効果的に対応する一方で、限界もあります。モデルの性能分析からは、強引な走行 や 後方交通の見落とし といった具体的な失敗パターンが明らかになり、今後の改善に向けた方向性を示しています。

強引な走行

後方交通の見落とし

保守的な (安全マージンを大きく取った) 停止
@inproceedings{rawal2026nord,
title={NoRD: A Data-Efficient Vision-Language-Action Model that Drives without Reasoning},
author={Rawal, Ishaan and Gupta, Shubh and Hu, Yihan and Zhan, Wei},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}リサーチ サイエンティスト
Applied Intuition のリサーチ サイエンティスト。生成 AI と自動運転を専門とする。スタンフォード大学にて電気工学の博士号を取得し、自動運転車輌向けの高信頼ローカライゼーションを研究。スタンフォード大学では、ニューラル マッピングとナビゲーション システムに関する博士研究員としての研究にも従事。
リサーチ インターン
Applied Intuition のリサーチ インターンとして、自動運転向け vision-language-action (VLA) モデルのポスト トレーニングに携わる。テキサス A&M 大学にてコンピューター サイエンスの修士号、ビルラ工科科学大学ピラニ校にてコンピューター サイエンスの工学士号を取得。

