品質メトリクスにより AEB 再シミュレーションの失敗率を 73% から 3% に削減
このブログ記事では、品質指標がどのようにして再シミュレーションの失敗率を73%から3%に低減させると同時に、有効なAEBテストデータを87倍に増やすことができたのかについてご紹介します。
皆さんのチームは、すべてのプロセスを正しく実行し、大規模な車両フリートデータを記録し、正常にログをアップロードし、AEB オープンループの再シミュレーション作業を一括実行していますが、その 70% 以上が失敗に終わっています。これは架空のシナリオではありません。これは、品質指標が導入される前に、フリートデータパイプラインで繰り返し発生していた実際の失敗率です。
ほとんどのデータパイプラインは、ある単純な前提に基づいて構築されています。ログが正常にアップロードされたならば、すぐにシミュレーションに使用できるという前提の下、ファイルは存在し、サイズは正しく、転送エラーはないと想定されています。
しかし、現実は非常に脆弱な環境にあります。アップロード検証をすべて通過したログであっても、特定の時間区間において重要な信号データが欠落している可能性があり、これは GPUジョブが実行され、シミュレーションスタックが必要なデータを見つけられずに失敗するまでは明らかになりません。これは稀に発生するエッジケースではなく、車内で動作する記録システムの構造的な特性に起因する問題です。そして、このような不良データは一度の失敗で終わるのではなく、その後の各段階で問題を増幅させます。
フリート規模で見ると、このような連鎖は多大なコストにつながります。無駄になる GPU 演算リソース、重複保存コスト、そしてデバッグに費やされるエンジニアリング時間を合わせると、年間でかなりのコストが累積します。さらに、実際には有効であるにもかかわらず使用できないと判断され、埋もれてしまったテストデータの機会費用まで考慮すれば、その影響はさらに大きくなります。

品質検証パイプラインに入力される ADAS センサーデータ
走行ログは、記録システムと下流の安全性検証側で「完全性」の定義が異なるため、表面化しないまま失敗を招くことがあります。記録システム側は、すべてのファイルが書き込まれ転送されればログは完全であるとみなします。シミュレーションスタック側も、理論上は入力データの欠損を許容できるほど堅牢に設計することは可能です。
しかし、AEB のような安全に関わる重要機能において、劣化した入力データを隠蔽し、システムの補完能力に依存することは根本的に誤ったアプローチです。アクティブセーフティにおいて正しい原則とは、入力データの品質を担保することであり、データ欠損を許容するのは、検証済みの代替戦略 (例:トンネル内での GPS 中断を、信号が復帰するまでオドメトリやマップマッチングで補完するなど) が定義されている場合に限られます。こうした戦略を伴わないデータ欠損は、シミュレーションの入力として容認されるべきではありません。この考え方の違いは、あらゆるフリートデータパイプラインに共通する 3 つの典型的な失敗パターンとして現れます。
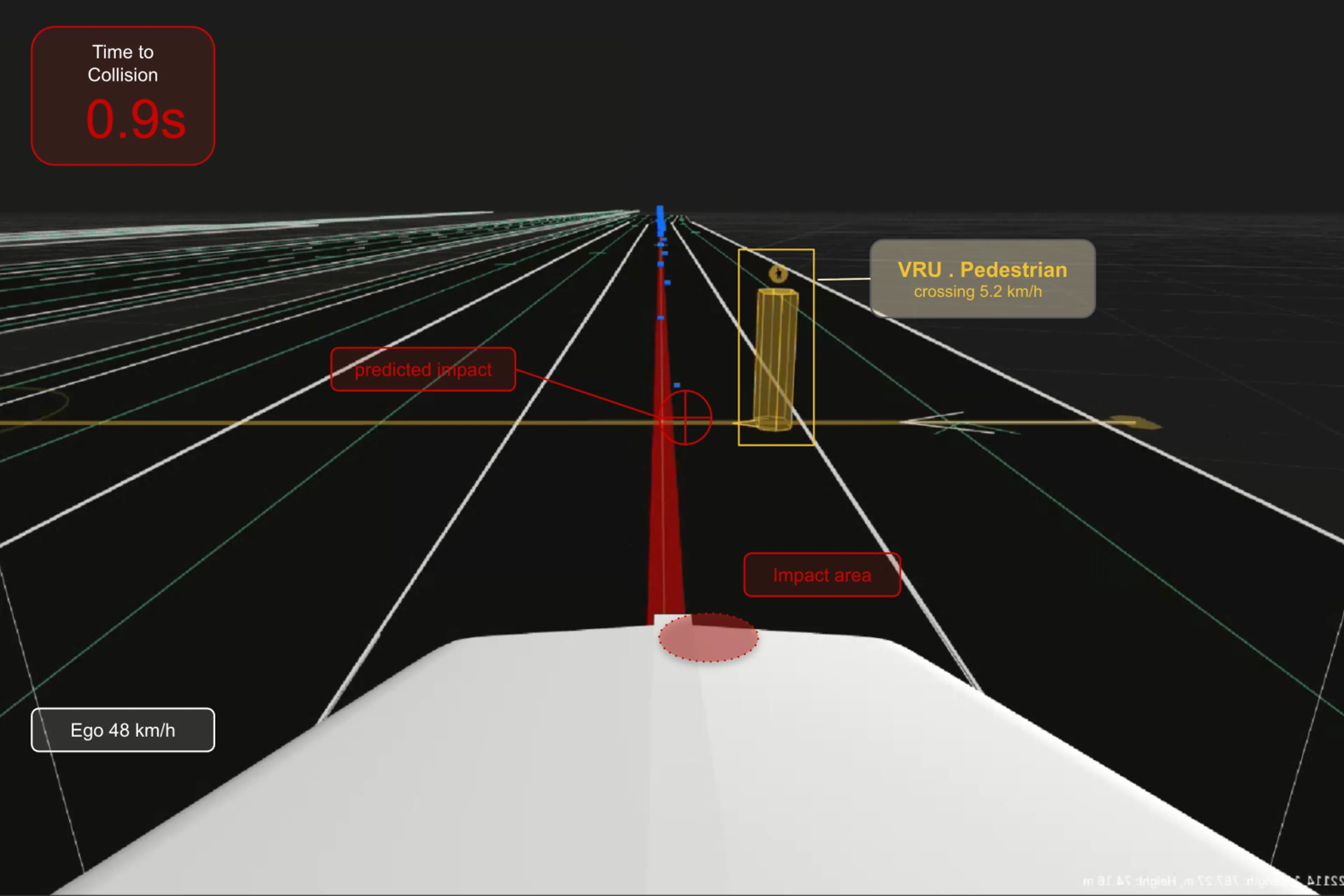
ドライブバイワイヤのフィードバックは 50 Hz で出力され、車両ダイナミクスに関する各信号を提供。中でも最も重要なのが前後速度であり、AEB 機能はこの値を用いて衝突までの時間を算出、緊急ブレーキの要否を判断します。さらに、ターゲット選択のための経路予測には、ヨーレートやステアリング角度といった信号が不可欠です。
アクティブセーフティにおいて、こうしたフィードバックが数秒間でも欠如し、かつ代替経路も存在しない状況は許容されません。ブレーキ判断の根拠となる信号がない以上、AEB の挙動を安全に評価する術はないからです。一般的なフリートデータでは、カメラやレーダーに中断がなくとも、CAN 信号のみが数十分にわたって欠落しているログが散見されます。ファイルレベルで異常がなくとも、シミュレーション側はこうした不完全な入力に対する結果の生成を正当に拒否。信頼性の低い評価を出力する代わりにタイムアウトを選択するため、欠損期間中のセグメントは一切活用できなくなります。
メッセージが全く記録されていない区間は、主に 3 つの状況で発生します。まず、レコーダーが書き込みを開始した後にセンサーが初期化される「ログ開始時」。次に、シャットダウンシーケンス中の「ログ終了時」。そして、ドライバーが走行の合間に一時停止し、記録システムが動作し続ける一方で一部のトピックが停止する「ログの中間地点」です。
いずれのケースにおいても、該当するセグメントに有効な走行シナリオは含まれていません。しかし、標準的な品質メトリクスである「メッセージ間の最大時間差」を用いると、完全に空のセグメントは 0.0 と計測されます。その結果、多くのフィルタリング条件をすり抜けてしまいます。こうした空データが混入すると再シミュレーションは失敗するため、ログ内の位置に関わらず、これらを明示的に検出し除外する仕組みが不可欠です。
AEB の再シミュレーションを実行するには、特定のトピック群が同時に存在し、かつ連続していることが必須条件となります。具体的には、自車両のポーズ、車両ダイナミクス、物体検出、そして車線情報です。アクティブセーフティのセンサー構成が進化するにつれ、この要求セットも拡張されます。たとえば、レーダーチャネルは AEB のターゲット構成における不可欠な要素です。
既存のパイプラインにおいて、カメラに対する品質メトリクスは整備されていても、AEB にとってクリティカルな車両バスやレーダー信号まで網羅されているとは限りません。セグメント内でトピックが 1 つでも欠落すれば、シミュレーションは有効な評価値を生成できなくなります。
そのため、品質メトリクスのフレームワークには拡張性が求められます。新たなセンサー種別の追加に対しても、インフラの改修ではなく設定変更のみで対応できる柔軟性が重要で、現在必要とされるすべてのトピックをカバーするメトリクスが備わっていなければ、不適切なセグメントを実行前に排除することは不可能です。
これらの失敗パターンを解消するには、品質評価のタイミングを再シミュレーションのトリガー時ではなく、データ取り込み時へと前倒しする必要があります。基本構成としては、取り込み時に固定長 (30 秒) のセグメント単位で品質メトリクスを算出し、クエリ可能なテーブルに保存。下流のワークフローを実行する前にそのメトリクスを参照する仕組みを構築します。
各トピックに対し、メッセージ数 (データの有無) とメッセージ間の最大時間差 (データの連続性) という 2 つのメトリクスを用意すれば、前述した 3 つの失敗パターンをすべてカバーできます。フィルタリングの際は、これらの数値をワークフローごとの閾値と照合。たとえば AEB の再シミュレーションでは、4 つの必須トピックすべてにおいて、max_gap ≤ 1.0 秒 かつ message_count > 0 を同時に満たすことが条件となります。物体シミュレーションやトレーニングデータの抽出といった異なるワークフローでも、保存済みの共通メトリクスに対して異なるトピックセットや閾値を適用できるため、データの再取り込みは不要です。
フィルタリングされたセグメントを実行可能なバッチに変換するには、さらに 2 つのステップを要します。まず「チェーン検出」により、品質条件を満たす連続したセグメントをひとつの区間としてグループ化し、ジョブのタイムアウトを避けるために長すぎる区間を分割。次に「インターバルベースのリカバリ」によって、欠損を含むログ全体を破棄するのではなく、欠損箇所の前後に存在する有効なデータを特定して活用します。

信号カテゴリ別・経時的な品質フィルターの失敗率
Applied Intuition のデータエンジンは、フリートデータの収集、取り込み、エンリッチメント、探索、シミュレーション、そして検証までを網羅したエンドツーエンドなプラットフォームの一部として、このアーキテクチャを実装。品質メトリクスは、アップロード後の取り込みパイプラインにおいて Spark ジョブで算出され、Trino からクエリ可能な Hudi テーブルに格納されます。これは後付けのツールではなく、シミュレーションをトリガーする同一プラットフォームに組み込まれた機能です。
このケーススタディでは、エンジニア 1 人が既存の 47 以上のセンサーメトリクスに対し、AEB 向けの新たなメトリクスを 4 つ追加するだけで、従来のセットではカバーされていなかった車両バストピックへの対応を完了。新メトリクスの導入は設定の追加のみで済み、インフラの変更は不要です。
メトリクスが整備されれば、単一の CLI コマンドでメトリクステーブルをクエリし、有効な区間を特定、バッチ実行可能なチェーンを構築してジョブを投入。このコマンドは、閾値の設定や実行時間の上限、ドライランモードにも対応しています。新たな品質課題が発生した場合でも、一人のエンジニアが取り込み工程まで遡って原因を特定し、メトリクスの追加や過去データのバックフィルを行い、数日で修正を展開。分断されたマルチベンダーのツールチェーンでは、同様のサイクルに通常数か月にわたるチーム間の調整を要します。

Applied Intuition のクローズド ループ型データ エンジン パイプライン
ここで示す主要な数値は、限定された収集期間内の代表的な単一バッチに対し、品質フィルタリングとインターバルベースのリカバリを適用した結果です。再シミュレーションの失敗率は 70% 以上から 3% 未満へと激減し、同一の走行ログから抽出可能な有効テストデータの量は 87 倍に増加。この劇的な改善は、追加の走行データを収集した成果ではなく、既存データの中から有効なものを正しく特定したことで実現しました。
同一の品質重視ワークフローを、特定の収集期間における単一車両の全データへ適用したところ、データ利用率は 74% に到達。これは、収集された生データのほぼ 4 分の 3 が、品質フィルタリングを経て AEB 再シミュレーションに直接活用できる状態になったことを意味します。
品質フィルタリングを一度実行すれば当面の問題は解消されます。しかし、モニタリングレイヤーを継続的に運用することで、次なる課題がシミュレーション工程へ到達すること自体を未然に防げます。
データエンジンは、このワークフロー向けに 2 つの専用ダッシュボードを提供。まず「AEB テストログ品質モニタリングダッシュボード」では、フリートログ全体のトピック別ヒートマップやギャップ検出、取り込み時に更新される品質トレンドを可視化します。次に「AEB 誤検知モニタリングダッシュボード」では、再シミュレーション結果に基づく 1,000 km あたりの FP 率を追跡。これにより、データ品質と走行機能の信頼性との相関を正確に把握できます。
重要なのは、品質トレンドが GPU ジョブのクラッシュ後ではなく、実行前にデータ収集チームやスタック性能チームへフィードバックされる点です。高い失敗率の改善に寄与したインフラそのものが、次の問題を未然に防ぐための継続的なシグナルを生み出します。
再シミュレーションの失敗率が 70% を超える状況は、一見シミュレーション側の問題に思えます。しかしその実態は、データの取り込みから実行トリガーまでの間に、要件確認の仕組みが欠落していた「ツールチェーンのギャップ」に他なりません。分断されたマルチベンダーの環境では、この解消に数週間のチーム間調整を要しますが、統合プラットフォームなら一人のエンジニアが数日で完結可能です。
この修正により、既存のフリート内に眠っていた有効な AEB テストデータが 87 倍も存在すると判明。フル車両構成での収集データに適用した結果、全記録時間の 74% が AEB オープンループ再シミュレーションに直接利用可能であると裏付けられました。大規模な再シミュレーションの信頼性向上は、単なるエラー削減に留まらず、既存データから統計的に有意な ADAS 検証を引き出すことに本質的な価値があります。
この成功パターンは現在も拡大中で、AEB 搭載車両の全走行データでこのワークフローが稼働しており、LDW の誤検知モニタリングも同様のプロセスへ移行。今後は同一のエンジニアが同じパイプラインを活用し、インフラ改修なしで ODD カテゴリへと対象を広げる予定です。取り込みから結果出力に至るまで、アクティブセーフティのモニタリング全体を一人のエンジニアが完結できる体制が整っています。
もし、再シミュレーションの失敗率が改善しない、あるいは有効なテストデータが埋もれている懸念があるならば、データエンジンの品質メトリクスとモニタリングをぜひ直接お確かめください。本記事の数値をベンチマークとしたパイプラインの評価やデモのご依頼については、Applied Intuition チームまでお気軽にお問い合わせください。
Solution Engineer
大学名については、日本語読者にもわかりやすいように、日本語名に加えて、必要に応じて英語で一般的に使われる略称や通称を括弧内に併記しています。
例:カリフォルニア大学バークレー校 (UC Berkeley)
v
プロダクト マネージャー
Applied Intuition のプロダクト マネージャー。領域を横断してフィジカル AI 向けのデータおよびシミュレーション プラットフォームの構築に携わる。自動運転とロボティクスにまたがる経験を持ち、ロボティクス スタートアップを創業して率いたほか、イスラエル軍情報部の特殊作戦技術部隊に所属。
ソフトウェア エンジニア
Applied Intuition のソフトウェア エンジニア。ADAS および自動運転システム向けの行動計画、環境モデリング、状況評価において約 20 年の経験を持つ。シュトゥットガルト大学にてコンピューター サイエンスの博士号を取得。